
Extensive Genome-Wide Variability of Human Cytomegalovirus in Congenitally Infected Infants
Research has shown that RNA virus populations are highly variable, most likely due to low fidelity replication of RNA genomes. It is generally assumed that populations of DNA viruses will be less complex and show reduced variability when compared to RNA viruses. Here, we describe the use of high throughput sequencing for a genome wide study of viral populations from urine samples of neonates with congenital human cytomegalovirus (HCMV) infections. We show that HCMV intrahost genomic variability, both at the nucleotide and amino acid level, is comparable to many RNA viruses, including HIV. Within intrahost populations, we find evidence of selective sweeps that may have resulted from immune-mediated mechanisms. Similarly, genome wide, population genetic analyses suggest that positive selection has contributed to the divergence of the HCMV species from its most recent ancestor. These data provide evidence that HCMV, a virus with a large dsDNA genome, exists as a complex mixture of genome types in humans and offer insights into the evolution of the virus.
Published in the journal:
. PLoS Pathog 7(5): e32767. doi:10.1371/journal.ppat.1001344
Category:
Research Article
doi:
https://doi.org/10.1371/journal.ppat.1001344
Summary
Research has shown that RNA virus populations are highly variable, most likely due to low fidelity replication of RNA genomes. It is generally assumed that populations of DNA viruses will be less complex and show reduced variability when compared to RNA viruses. Here, we describe the use of high throughput sequencing for a genome wide study of viral populations from urine samples of neonates with congenital human cytomegalovirus (HCMV) infections. We show that HCMV intrahost genomic variability, both at the nucleotide and amino acid level, is comparable to many RNA viruses, including HIV. Within intrahost populations, we find evidence of selective sweeps that may have resulted from immune-mediated mechanisms. Similarly, genome wide, population genetic analyses suggest that positive selection has contributed to the divergence of the HCMV species from its most recent ancestor. These data provide evidence that HCMV, a virus with a large dsDNA genome, exists as a complex mixture of genome types in humans and offer insights into the evolution of the virus.
Introduction
Human cytomegalovirus (HCMV) is member of the β-herpesvirus family. It is a ubiquitous, opportunistic pathogen, with seroprevalence of 30–90% in the United States [1]. In healthy individuals, primary HCMV infection is usually asymptomatic or can result in a mild febrile illness. However, infection persists throughout the life of the host. HCMV infections can be problematic for those with compromised or immature immune systems. For example, congenital HCMV infection is the leading cause of birth defects resulting from an infectious agent, affecting about 0.5% of all live births [2] and costing the U.S. Health care system ∼$2 billion annually [3]. Long term sequelae of congenital HCMV infections include deafness, blindness and/or mental disability [4].
HCMV contains the largest genome of any human virus with a dsDNA genome of ∼236 kilobase pairs [5]. Sequence analysis predicts that the genome encodes approximately 164 open readings frames (ORFs) [6]. The genome contains two unique regions (termed UL and US) that are flanked by repeats (termed RL and RS) both internally and terminally, although the internal RL region is not present in clinical isolates or low passage strains. Previous work with cell culture passed virus has shown that the genome of HCMV displays sequence variability. For example, the laboratory strain AD169 is a highly passaged, attenuated variant. The genome of AD169 as compared to low passage strains has an approximately 15 kb deletion which encodes an additional 19 or 22 open ORFs, referred to as the UL/b' region [6], [7], [8]. Approximately 20 ORFs of HCMV have been shown to exhibit nucleotide variability when sequenced from infected hosts [9], [10], [11], [12], [13], [14], [15], [16], [17], [18], [19]. These studies have often focused on the variability of ORFs encoding envelope glycoproteins or ORFs of UL/b', which are thought to be important for pathogenesis. As examples, UL55 and UL73, encoding the gB and gN glycoproteins, respectively, commonly exist as one of 4 genotypes, with less common genotypes also identified [19], [20]. In the UL/b' region, UL144, encoding a TNF-α receptor [21], and UL146 and UL147, encoding α-chemokines [22], also show significant variability among hosts [9], [14], [23], [24], [25].
Although it is known that HCMV is polymorphic among hosts, the source of the variability remains unresolved. There are at least two possibilities to explain the observation. The first is that de novo mutations arise upon introduction into a new host, resulting in a unique strain for each individual. The second possibility is that multiple HCMV genotypes exist within each host, and infection into a new host represents a selection event whereby a new dominant genotype is selected for and detected in subsequent assays. In support of this model, others have found evidence of mixed genotype populations at the few loci examined. Mixed populations have been observed when measuring gB genotypes [26], [27], [28], [29], [30], though the phenomenon has also been shown for other ORFs, such as gN, gO, gH, gL, UL139, and UL146 [31], [32], [33], [34], [35], [36], [37]. Furthermore, mixed populations have been shown in a range of patient populations, including immunocompetent, asymptomatic adults [31] and have been shown at multiple loci simultaneously [33]. While definitive relationships between genotypes and diseases are lacking, there is mounting evidence that mixed genotype infections serve as markers of severe or prolonged complications from HCMV infections [26], [27], [29], [30], [34], [36]. A shortcoming of the mixed genotype studies has been limited coverage of the HCMV genome. To our knowledge, less than 5% of the HCMV genome has been sequenced from clinical specimens in these types of studies (Figure S1). Thus, a remaining question is whether HCMV diversity is limited to a subset of ORFs or is found throughout the genome.
From earlier studies, it appears that HCMV may exist as a mixture of genotypes. Due to limitations of previous technology, it was unrealistic to study mixed HCMV populations to great depth or sequence the HCMV genome to high coverage. To address these shortcomings, we have adapted high throughput sequencing to sample many members of the HCMV genomic population, rather than just a dominant member. With the improved output of next generation sequencing, we were able to take a genome wide approach and sequence thousands of HCMV genome equivalents from each patient sample. Here we sampled the HCMV genomic populations present in urine samples collected from three congenitally infected newborns. These data reveal a high level of intrahost variability and offer strong evidence that HCMV exists as a complex mixture of variants. We also found evidence of selection at both the intrahost and interhost levels, highlighting evolutionary forces that shape the HCMV genome. These results greatly improve our understanding of the structure of HCMV populations in humans, and have important implications for the study of DNA viruses.
Results
Development of sequence methodology and error filtering protocol
In clinical samples, HCMV DNA represents a very low proportion of the total DNA. Thus, direct sequencing would yield a low depth of the HCMV population with human DNA being a major source of contaminant. Because there is homology between the human and HCMV genomes [38], [39], this contaminant would be problematic in downstream sequence analyses. We developed a series of approximately 70 long range, overlapping PCR reactions to selectively amplify the entire HCMV genome. However, PCR amplification can introduce errors of its own, which could be misinterpreted as polymorphisms. To assess the error associated with sample processing, we resequenced BACs that contained the genomes of the HCMV strains AD169 and Toledo. The BACs have been shotgun sequenced to a 10X depth [40], producing reliable reference sequences for these purposes.
The BAC DNA was amplified through a series of PCR reactions and sequenced on the Illumina GA II paired end platform. The sequence output was equivalent to ∼220 genomes per strain (Table 1). The sequence reads were aligned to the appropriate reference sequence and the alignments were analyzed for errors. We assumed that all mismatches between the sequencing reads and the reference sequence were errors introduced by either PCR or sequencing. This assumption is most likely conservative because there is the possibility that variants were created by propagating the BACs in E. coli or that errors could be present in the reference sequences. The alignment data contained in the pileup file was then processed with a variant filtering program. The variant filtering program only outputs variants that are above threshold values for basecall quality, mapping quality, depth at the position, number of occurrences of the same variant and frequency of the variant in the data. The thresholds used were: basecall quality ≥30, mapping quality ≥89, depth ≥15, number of occurrences ≥3, and frequency ≥.019. The basecall quality and mapping quality values are used to filter nucleotides with low confidence from sequencing or from reads that align with low confidence, respectively. Depth, number of occurrences of variant and frequency are used to remove likely errors because random errors (from either sample amplification or sequencing) have the highest likelihood of occurring as singletons and doubletons (1 or 2 occurrences). These threshold values were chosen by training the filtering program with BAC resequencing data. The resequencing data from AD169 and Toledo were mixed in various ratios to model a mixed population. The filtering thresholds were selected to increase specificity of detecting true variants; however, they carry a penalty of reducing sensitivity and underestimating the amount of variants in the sample (Table S1). The number of false positives remains low at various depths and mixtures of the sequences. We did not find evidence of amplification-induced skewing of variant frequencies. Further discussion of analysis of error can be found under Materials and Methods and Supplemental Information.

High throughput sequencing of clinical populations
We sampled HCMV genomic populations present in the urine collected from 3 HCMV-positive neonates within 2 weeks of birth (identified as U01, U04, and U33). The entire HCMV genome was amplified as discussed above. The PCR reactions and amount of template DNA were identical between the BAC resequencing and the clinical sequencing. Therefore, the error filtering protocol developed through BAC resequencing can be applied to the clinical sequence data. From clinical sequencing, >300 megabases of output per sample yielded an average depth of 1843 genome equivalents and an average genome coverage of 97.8% for the 3 samples (Table 1 and Figure S3).
Initially, the sequence reads from the urine samples were aligned to the sequence of the Merlin strain, which was used as the HCMV reference genome (Ref Seq ID: NC_006273). From the alignment, >104 single nucleotide variants (range: 11289–15709) were detected per viral population. Variants segregated into clusters at frequencies ≤.1 or ≥.9 (Figure 1). Variants with frequency ≤.1 represent on average 73% (Range 67%–78%) of the total and variants with frequency ≥.9 represent 20% (Range: 16%–24%). From these data, we conclude that the high frequency variants result from the major alleles found in the viral population while the low frequency variants result from the minor alleles.

Generation of a sample specific genome type
To study HCMV intrahost variability, we defined the major HCMV genome type of each sample and called intrahost variants from this reference genome type (Figure S4). A genome type is the genome wide analog of a genotype [41], [42], [43]. The major genome type contains the major allele found at every position of the genome. Thus, any variants from this genome type represent minor alleles or minor variants. It should be noted that the genome type may not represent any single DNA molecule in the viral population. Rather, the major genome type is a computational tool that allows for the detection of minor variants in the population, and every position of the genome in this analysis and all later analyses are treated independently (i.e. unlinked).
To define the major genome type, output from an initial alignment to Merlin was used to detect variants with frequencies >0.5 (Figure S4). These variants were interpreted to represent the major allele of the sample at each position. Variants were incorporated into the reference sequence to create an initial sample-specific genome type. Reads that did not initially align were used as substrate for de novo contiguous sequence (contigs) assembly. The contigs were aligned to the initial sample-specific genome type and incorporated into the genome if sequence identity was found. This modified genome type was used to serve as the reference sequence for another round of alignment of the sequencing reads and subsequent incorporation of high frequency variants and assembly of contigs onto the sample specific genome type. This process of constructing a sample-specific genome type was repeated until no additional reads were aligned between rounds of building the genome type (usually 4 rounds). At the end of the process, a single sequence was produced that represents the sample-specific genome type and contains the major nucleotide of the sample at every position of the genome. Lastly, the sequence reads were aligned to this genome type, and the alignment was used to call intrahost variants and to quantify intrahost diversity.
Intrahost HCMV populations are diverse
Intrahost variants were classified by ORF to quantify both intergenic and genome wide variability (Table 2, Table S3 and Figure 2). There were >8,500 intrahost variants in each sampled population. (Range: 8,562–13,335) (Table 2), and ∼91% of the variants were present at frequencies <0.1. We compared the levels of variants from clinical sequencing and BAC resequencing to determine the level of false positives or errors within the clinical data. The false positive rate was reduced to 6.7% with filtering (Figure S2).

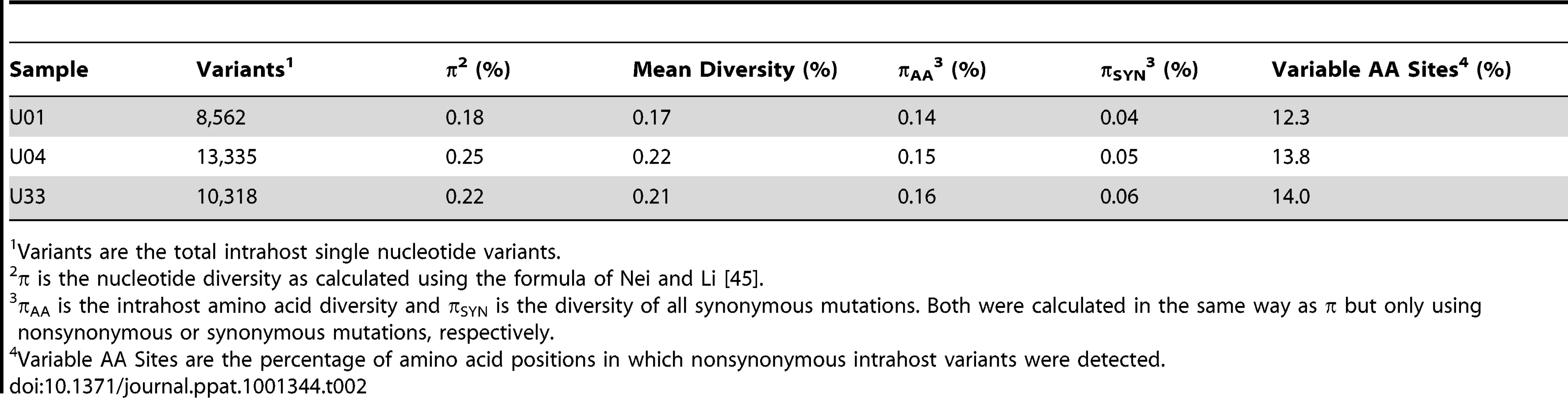
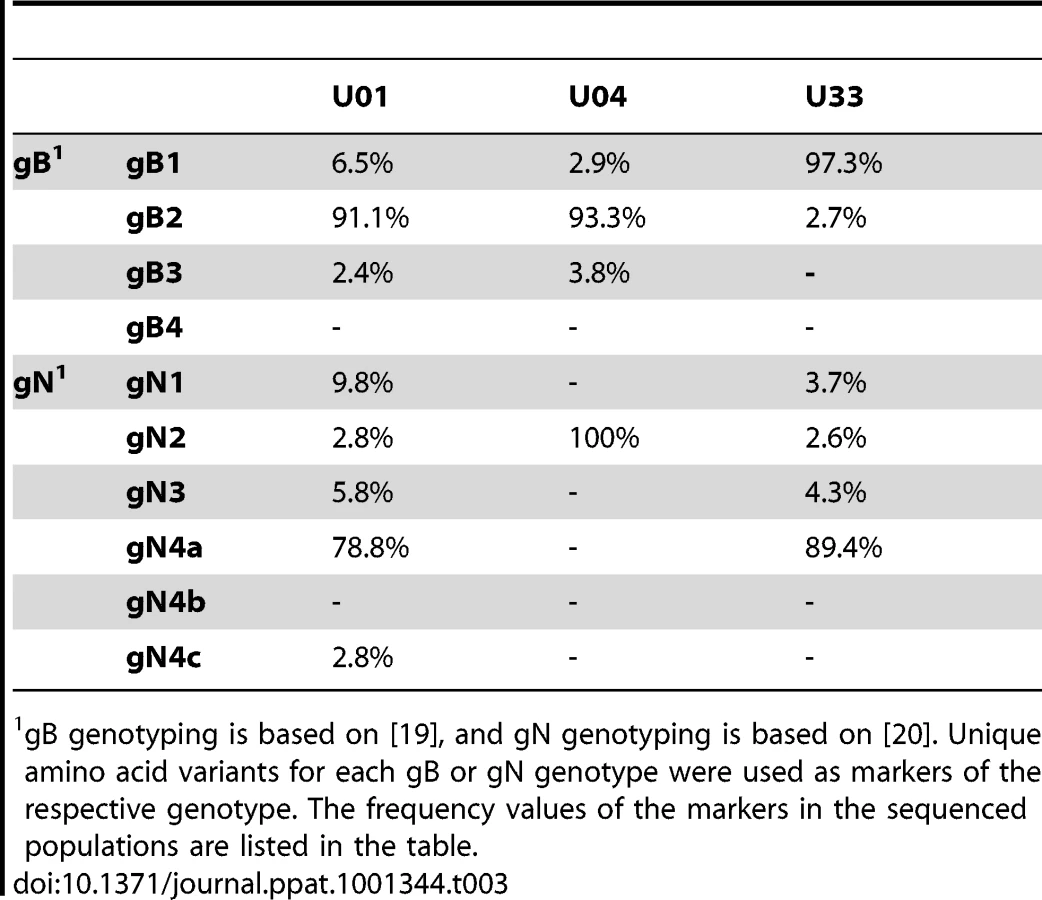
Our initial analysis of the intrahost variability focused on the ORFs encoding the glycoproteins, gB (UL55) and gN (UL73). These ORFs have well defined genotype classifications [19], [20] and previous studies have shown mixed genotype populations for these ORFs [27], [44]. Full genotypes cannot be determined using short read sequencing because linkage information is lost between regions larger than a sequence read (i.e. 72 nt in this work). We analyzed the presence and frequency of amino acid variants that are markers of gB or gN genotypes as a substitute for full-length genotype data. For example, at position 181 of gB, a lysine is unique to the gB2 genotype and an arginine is unique to gB3 [19]. K181 or R181 within gB serves as a marker of these two genotypes. The frequency of these markers is the inferred frequency of the full-length genotype. We determined that mixed genotype populations existed for the gB (UL55) and gN (UL73) loci in congenitally infected infants in agreement with previous studies [27], [44] (Table 3). However, these data represent ∼0.5% of the HCMV genome, and led us to determine whether evidence of mixed populations exists throughout the genome.
To further define the intrahost diversity of HCMV populations, we first analyzed the genome wide data at the nucleotide level. We used the measures of nucleotide diversity (π) [45] and mean diversity [46], which were calculated as averages for all ORFs of the HCMV genome (Tables 2 and S3 and Figure 2). π is the average pairwise distance of sequences in the population, and mean diversity is the percentage of variant sequence within the population. The genome wide average for π for the 3 samples was 0.22% (Range: 0.18%–0.25%). As a point of comparison, this value is similar to the genome wide π for HIV [47] and the single ORF intrahost π of other RNA viruses, such as hepatitis C, dengue, and West Nile [48], [49], [50], [51] (Figure 3 and Table S4). Single ORF intrahost π was as high as 0.64% for HCMV. The HCMV genome wide mean diversity was 0.20% (Range: 0.17%–0.22) and is similar to that of HIV-1 and dengue virus [46], [50]. Figure 2 also reveals that intrahost diversity was not limited to a few loci but was found within most ORFs. The ORFs encoding gB (UL55) and gN (UL73) were in the 32nd and 20th percentile for ORF intrahost diversity, respectively, (Table S3) and do not reflect the genome wide diversity. Therefore, HCMV populations are variable and using unbiased, genome wide data for studying that diversity offers an advantage over previous techniques that have focused on a limited set of loci.

We grouped ORFs by gene product function or expression kinetics using the classification of Sylwester et al. [52] to further investigate the patterns of intrahost diversity (Figures 4 and S6). However, there was considerable variation of sequencing depth of some ORFs (Table S3) raising the possibility that uneven sequencing depths could influence this analysis of diversity. Indeed, there was a correlation between nucleotide diversity of an ORF and the extremes of sequencing depth (Figures S5A). To reduce the influence of excessive depth on the analysis, we focused on ORFs with sequencing depths between 15 and 1200 (n = 338) (Figure S5B). In this range, the influence of depth on nucleotide diversity will be ∼.01%, which is approximately the level of noise generated from errors in BAC resequencing. After selecting for ORFs sequenced to depths within this range, we did not observe significant difference nucleotide diversity across expression class. However, we did find a statistically significant association between ORF function and intrahost nucleotide diversity (p <.0001) (Figure 4 and S6). ORFs encoding glycoproteins showed a reduced level of intrahost nucleotide diversity. This latter result was unexpected given that glycoproteins were the most frequently analyzed in earlier studies of intrahost variability.

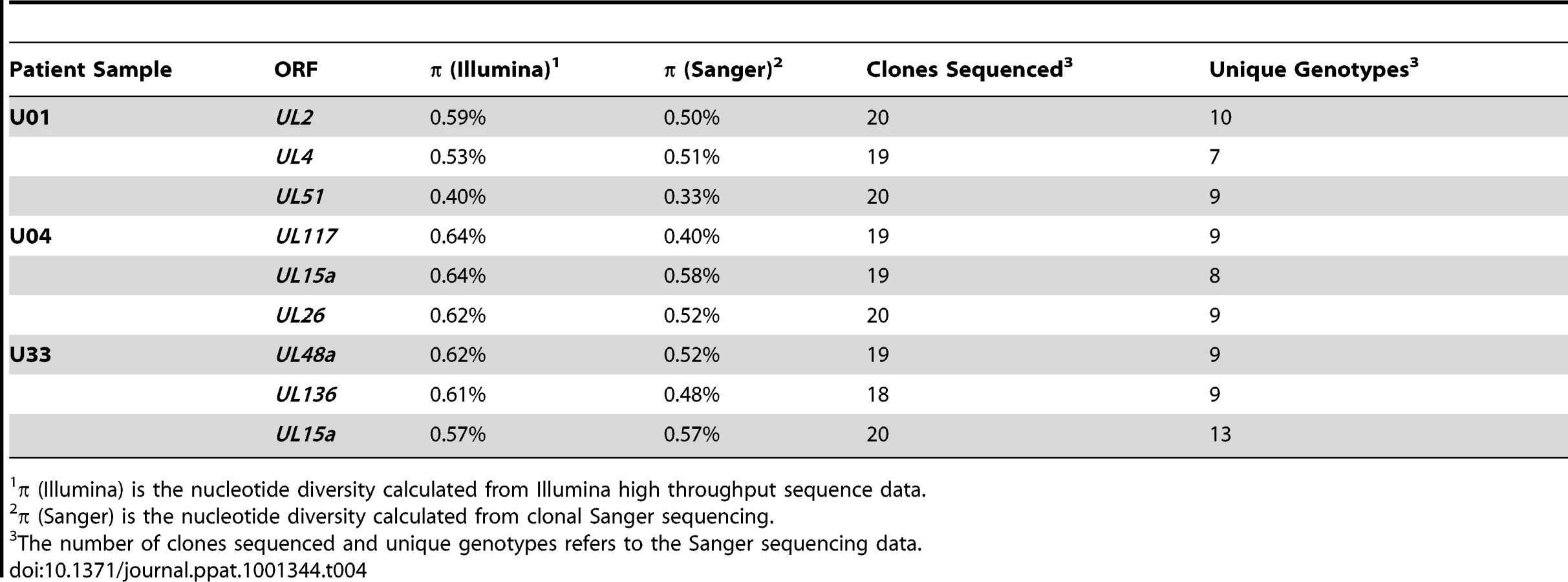
To confirm the results obtained via high throughput sequencing, we assayed for π and genotype distribution by clonal Sanger sequencing of three highly variable ORFs in each patient sample. We found that the major genotype detected in both methods is the same (data not shown). Also, the values for π determined by both high throughput and Sanger sequencing were generally similar for each ORF (Table 4). Clonal Sanger sequencing of these ORFs revealed a high density of unique genotypes in the clinical samples, with as many as 13 unique genotypes from 20 clones. The Sanger sequence data was also used to generate unrooted phylogenetic trees (Figures 5 and S7). Within the trees, we have included major genotype sequence data from the other patient samples in this study to provide perspective on the diversity of the clones. In some Sanger datasets, the diversity of clones could be explained by one or two mutational steps from the major genotype (Figure 5A). Other datasets revealed clones within a patient sample that were more divergent than sequences among patient samples (Figure 5B). This result could represent a highly mutagenic viral population, a co-infection with two or more strains, mixtures of viral variants from different compartments, or a combination of these mechanisms. An interesting side note is that, in a single patient sample, there is evidence for diversity from a few mutational events (Figure 5C), and possible evidence of co-infections (Figure 5D). Thus, the mechanism(s) that leads to the diversity of HCMV populations may be complex.

Because the coding sequence of HCMV populations appeared to be highly variable, we next investigated whether there were differences in variability between coding and non-coding regions of the genome. For this analysis, coding regions were defined as protein coding sequences, and non-coding regions comprised the remainder of the genome. Thus, the non-coding regions likely contain functionally important sequences due to the inclusion of regions such as the origin of replication, transcription factor binding sites and miRNA sequences. Using these parameters, we found that there was a statistically significant difference between intrahost diversity of the coding and non-coding regions (Table 5). The coding regions had higher nucleotide and mean diversity values than the non-coding regions; however, the average frequency of coding variants was significantly less than the average frequency of non-coding variants. Although the differences in values for these summary statistics are small, as seen in the U04 population, it should be noted that coding and non-coding variants are interspersed across the genome. Thus, this proximity should allow for statistical robustness and may reflect a fine-scale mechanism regulating the amount and frequency of coding and non-coding variants.

We next investigated the clinical HCMV populations at the amino acid level. The average intrahost amino acid diversity (πAA) was 0.18% (Table 2), which is comparable to RNA viruses such as dengue and West Nile [48], [50]. The diversity at nonsynonymous sites (πAA) was ∼3-fold higher than at synonymous sites (πSYN), suggestive of a slight excess of nonsynonymous mutations within the HCMV populations. The genome wide average for the percentage of amino acid sites that exhibited intrahost variability was 13.4% (Range: 12.3%–14.0%) (Table 2). This value reveals the substantial variation in intrahost coding potential of HCMV populations. Taken together, these data support a model of HCMV existing as diverse populations at both the nucleotide and amino acid levels. This result is novel for a large dsDNA virus, which encodes a DNA polymerase with exonuclease activity [53].
Evidence of positive selection in HCMV intrahost populations
Having found significant levels of intrahost variability, we felt it was important to determine whether the patterns in variability were the result of genetic drift (i.e. neutrality) or if selection could explain the observed variant frequency patterns in the populations. We applied the model of Nielsen et al [54] to detect selective sweeps within the genome wide variant data. Selective sweeps are caused by positive selection and result in reduced variability around the region under selection [55], [56]. Importantly, the test of Nielsen et al is robust to demographic effects. This is a critical function because the HCMV populations under study have most likely undergone significant recent demographic changes, such as population bottlenecks and expansions associated with primary infection. The Nielsen approach is an outlier test that calculates the likelihood of a selective sweep based on the distribution of variant frequencies within a region as compared to the genome as a whole. The composite likelihood ratio (CLR) of the region is a measure of this comparison, with higher CLR values indicating the region is a more extreme outlier and thus, more likely a target of positive selection. Applying the model of Nielsen et al to the HCMV genome wide data, we identified an average of 9 ORFs per population (Range: 2–15) under statistically significant positive selection (Figures 6 and S8 and Table S5), including UL83 (pp65) and UL123 (IE1). While there was no overlap between the positive selected ORFs in the three samples, there was evidence of overlap in protein function. For example, UL102 in the U01 sample and UL105 in the U04 sample were targets of selective sweeps, and protein products of both ORFs are subunits of the helicase-primase complex. Many of the ORFs highlighted in this analysis have either poorly defined or no known function.

Interhost HCMV variability and selection
The generation of HCMV sequence data from urine specimens allowed for genome wide analysis of interhost polymorphisms across clinical samples, as opposed to those observed in laboratory passaged strains. For this analysis, polymorphisms were defined as variants from the HCMV reference sequence with frequencies >0.5, and are the same class of variants previously incorporated into a sample specific genome type. By resequencing HCMV BACs, we determined that the error rate for calling polymorphisms is 0.028%., i.e., ∼65 erroneous polymorphisms are called within a 236,000 bp genome type (Table S2). On average, there were ∼2600 polymorphisms per genome type resulting in an interhost variability of 1.1% at either the nucleotide or amino acid level (Table 6). Only 7.9% (612 of 7,780) of the nucleotide polymorphisms and 1.2% (25 of 2,129) of the amino acid polymorphisms were common among the 3 samples. This result shows that most of the polymorphisms are not only different between clinical populations and a laboratory passaged strain (Merlin), but they appear to be uniquely associated with the specific environments of the viral populations. Thus, these findings are consistent with previous work showing diversity of the HCMV species [5].

Next, we wanted to determine whether there is evidence of selection within the interhost sequence data. Previously, single ORFs of the HCMV genome have exhibited dN/dS ratios of less than 1 [57], [58], suggestive of negative selection. Using the genomic data, we calculated dN/dS values for all ORFs of the HCMV genome and also calculated a genome wide average. In agreement with previous studies [57], [58], the genome wide average dN/dS values were significantly below 1 (p <0.0001, G-test) (Table 6, Table S6 and Figure 7). Approximately 5% of ORFs exhibited dN/dS values greater than 1, which is suggestive of positive selection. To find patterns in the genome wide dN/dS values, ORFs were classified according to protein product function and expression kinetics (Figures 8 and S9). No significant association was seen between dN/dS and expression kinetics, but a highly significant association was observed between protein product function and dN/dS (p = 0.0002). Envelope proteins exhibited elevated dN/dS values and DNA replication proteins showed low dN/dS values (Figure 8).


We next used the McDonald-Kreitman (MK) test on the clinical sequence data to further analyze selective pressures. The input data for the MK test are the divergent (i.e. interspecies) nonsynonymous (DN) and synonymous (DS) mutations and the polymorphic (i.e. intraspecies) nonsynonymous (PN) and synonymous (PS) mutations [59]. Due to the inclusion of both polymorphic and divergent mutations, the MK test is a more sensitive test for selection than the dN/dS statistic. A 2x2 contingency table of the values is used to calculate significance of the mutational pattern and the respective ratios provide information regarding the direction of the test rejection. For example, positive selection is generally regarded to result in a (DN/DS)/(PN/PS) ratio >1, while negative selection results in a ratio <1.
A genome wide MK test was performed using sequences of all orthologous ORFs (n = 160) from Merlin and the three clinical samples with the inclusion of chimpanzee cytomegalovirus (CCMV) as the outgroup. Approximately 65% (n = 104) of ORFs were scored as neutral in this test. ORFs yielding (DN/DS)/(PN/PS) ratios significantly >1 were ∼4-fold more frequent than ORFs producing ratios significantly <1 (n = 45 and n = 11, respectively) (Table S7). This pattern could result from positive selection. However, considering the statistically robust, non-neutral dN/dS values, there is also widespread evidence of pervasive negative selection. Taken together, the results suggest that positive selection has driven the fixation of HCMV-specific mutations, and contributed to the divergence of the HCMV and CCMV species. However, demographic effects could also contribute to the observed mutational patterns and cannot be completely ruled out from these analyses, though considering inter-digitated synonymous and nonsynonymous sites ought to allow for a robust statistic.
Discussion
High throughput sequencing has dramatically increased the number of genomes sequenced and is a useful tool for analyzing populations present within various environments. Our work represents the first use of high throughput sequencing technology to study the intrahost genomic populations of a large DNA virus in clinical samples. We observed substantial intrahost variability that was found throughout the HCMV genome and found evidence of selection both at the intrahost and interhost levels.
An unexpected finding of this study was that almost every ORF of the HCMV genome showed some level of intrahost diversity in the three populations that were sampled. Thus, these results are an important extension of previous work that has revealed intrahost diversity within a small number of ORFs, including gB and gN [27], [44]. However, the present data suggest that genotyping may not be a reliable surrogate for measures of HCMV diversity in clinical specimens. For example, the gB and gN genotype data in Table 3 suggest that sample U01 is genetically the most diverse and U04 is the least diverse. However, Table 2 shows the opposite to be true. U01 is the least diverse and U04 is the most diverse for HCMV on genome wide scales.
By quantitating variability using the measure of nucleotide diversity, it can be seen how the intrahost diversity of HCMV is comparable to those of RNA viruses, including HIV. The similarity in values is striking considering the common assumption that RNA viruses exist in more highly diverse populations than DNA viruses due to the lower replication fidelity of RNA genomes. Thus, this work leads to a questioning of the source of the diversity observed in HCMV populations. One possibility is the prevalence of high mutation rates during replication of viral DNA genomes, similar to RNA viruses. This possibility does not seem likely considering that HCMV encodes a DNA polymerase with proofreading activity [53]. A second possibility is low mutation rates but high levels of replication, leading to an accumulation of mutations. In support of this model, it is suspected that only a single or very few virions cross the placenta to initiate a congenital infection. At the time of collection (<2 weeks postnatally), the samples contained ∼107 HCMV genome copies per mL of urine (data not shown). Thus, there had been many rounds of recent replication within the new host before the populations were sampled, which could lead to the accumulation of many variants even with a low mutation rate. Alternatively, the diversity could result from re-infection or co-infection. The phylogenetic trees of select ORFs (Figure 5 and S7) suggest that some ORFs are highly divergent from a central population of genotypes, which suggests re/co-infection events. However, phylogenetic trees for other ORFs reveal highly similar clones. More experiments are needed to sort out these possibilities.
Although the source of diversity is currently unclear, the existence of high intrahost diversity does lead to models of HCMV evolution. Creation of de novo mutations is stochastic and most likely occurs rarely, as suggested by the proofreading DNA polymerase encoded by HCMV. A high level of standing or pre-existing variation means that a pool of variants exists prior to the introduction of a new selective pressure. A low frequency variant(s) could quickly rise to high frequency because the selection coefficient of this allele could be increased under the new environmental conditions. Thus, diversity should offer a rapid mechanism of evolution for the virus in an environment of changing selective pressures. Alternatively, the low frequency variants could simply represent non-functional genomes or be reduced in frequency by negative selection. Data showing that the frequency of variants in coding regions is significantly lower than the frequency of variants in non-coding regions of the viral genome (Table 5) are consistent with this explanation. Again, it is possible that changing selective pressures could reverse this effect and cause a change in frequency of these variants. Future experiments should test the effect of changing selective pressures on the frequency of pre-existing variants in the population.
Analysis of the sequence data revealed evidence of selection within the viral populations. The results of the selective sweep analysis (Figure 6 and Table S5) are intriguing in the context of host-pathogen dynamics. Both UL123, encoding IE1, and UL83, encoding pp65, were found to be within regions of selective sweeps in one patient sample (U04). These proteins are demonstrated targets of CD8+ T cells in neonates with congenital infection [60] and suggest an immune-mediated mechanism of selection. This is the first evidence that known HCMV immune targets are also targets of positive selection. The selective sweep analysis also detected many ORFs with no known function. Whether these ORFs are under immune selection or are targets of positive selection for other reasons, such as tropism or viral replication, is still unknown.
We found evidence of both positive and negative selection within the genome when comparing interhost variation. The results suggest a model in which positive selection contributed to the divergence across the HCMV species, but genetic stability of the viral species is maintained with negative selection. Contrasting these long term selective forces to the observed high level of standing variation of the intrahost populations may lead to a clearer interpretation of the results. As mentioned above, the standing variation potentially reduces the time of adaptation to a novel environment or pressure. However, the negative selection acting on the variants may balance this phenomenon and prevent deleterious mutations from reducing the fitness of the overall HCMV species.
Two groups have recently reported using high throughput sequencing to study HCMV from clinical material. In the report by Cunningham et al [61], a major genome type sequence was generated from clinical material. In contrast, Gorzer et al [44]. studied genetic populations at three loci. These approaches are complementary to that presented here in which we sequenced HCMV populations on genome wide scales. As compared to the work of Cunningham et al, our study requires PCR amplification to select for HCMV DNA, which produces more HCMV-specific sequence data on a single sequencing run and greater depth of the viral population. This increased sequencing depth allows for a more accurate detection of minor variants within the population (Table S1). However, the approach by Cunningham et al differs from ours in that it allows for a more rapid sequencing of the major genome type, thereby producing greater sequence information about the HCMV species. In contrast, Gorzer et al sequenced three loci of the HCMV genome to a greater depth than our study, leading to higher levels of confidence in detecting minor and rare variants. However, our use of a genome-wide approach allows for unbiased detection of variability. As proof of the power of this approach, a commonly studied variable ORF, such as UL73 (gN), is in the lowest quintile for intrahost diversity, while many of the ORFs with the highest intrahost diversity have not been studied for variability. Therefore, a genome-wide study can highlight loci for future studies using ultra-deep sequencing.
The results presented here suggest that diversity of DNA virus populations should be studied more thoroughly to determine the universality of the high level of variability. For example, in this study we sampled HCMV populations from urine of congenitally infected children. It is unknown if the genomic populations sampled from urine are representative of the populations in other compartments of the host. Also, the levels of replication during congenital infections are very high, such that the diversity observed in asymptomatic, adult hosts may be much lower due to lower levels of replication and, therefore, fewer opportunities for mutagenesis. Alternatively, the chance of co - or re-infection in adults is much higher, possibly leading to more diverse populations. Others have shown that Marek's disease, another herpesvirus, virus exists as a collection of mixed genotypes in culture [62]. Thus, there is evidence of a similar phenomenon. Whether high diversity, mixed genotype populations exist for other herpesviruses or other dsDNA viruses outside of this family remains to be seen.
Materials and Methods
Ethics statement
Clinical specimens were obtained from neonates with congenital HCMV infection and de-identified prior to receipt by the investigators. Specimens were gathered as part of a standard clinical procedure. None of the investigators were involved in specimen collection. The use of these specimens for research was approved by the University of Massachusetts Medical School Institutional Review Board (IRB Docket # 10778).
Patient population, collection of samples and cloned viral DNA
Neonates within two weeks of age were diagnosed with congenital HCMV infection at the request of their respective care providers. The University of Massachusetts Memorial Health Center clinical virology laboratory performed diagnostic virus isolation. De-identified urine samples were then used for this study. No clinical information about the infants was available. Samples were stored at −80°C until DNA purification. DNA was purified using a Qiagen Blood and Tissue Kit using the standard protocol. HCMV BAC DNA has been described previously [40] and was kindly provided by Tom Shenk (Princeton University). Isolation of BAC DNA from E. coli strains was performed as described [63].
Amplification of HCMV DNA
We constructed a set of primer pairs spanning the entire HCMV genome. Primers were designed to anneal to conserved sites of the HCMV genomes, based on publicly available HCMV sequences. These databases included the sequence of an HCMV genome type (Strain 3157) that was produced directly from clinical material without amplification [61]. Primer homology with this strain supports the assertion that the chosen sites are found in wild type strains, and will reduce primer mismatch bias. Amplicons overlapped by ∼100–500 bp such that sequence was generated at primer binding sites from the adjoining amplicon. Using this overlap data, primers were reevaluated and redesigned primers as necessary, given that these new data potentially represent thousands of unique HCMV genomes per experiment. Lastly, primers were designed to have no or low homology to both human sequence and any other possible contaminating DNA sources, such as other herpesviruses or common human parasites and commensal bacteria.
Most amplicons were ∼6 kilobases (kb). Some were reduced to 3 kb if the original longer amplicon either gave no/weak amplification or non-specific products as determined by Sanger sequencing. Primer sequences used in this study are listed in Table S8. For BAC and clinical sample PCR amplification, initial PCR reactions were carried out using serially diluted templates to determine the lowest quantity necessary for efficient amplification. Quantitative PCR was performed using primers and probes described previously [64] and it was determined that each reaction contained ∼1300 HCMV genomes. The conditions for PCR were as follows: 1X PfuUltra II PCR buffer, 0.25 mM each dNTP (NEB), .25 uM each primer (IDT DNA), 0.5 uL PfuUltra II Polymerase (Agilent) and 1 M betaine. A touchdown PCR was run on an Eppendorf Mastercycler ep gradient S with the following program for all reactions: 98°C for 2 min, 5 cycles of 98°C for 30 s, 63°C (decreasing by 1°/cycle) for 30 s, 72°C for 2 min, followed by 25 cycles of 98°C for 30 s, 58°C for 30 s and 72°C for 2 min, with a 10 min final extension at 72°C. All amplified products were size-selected on agarose gels and gel purified. Because insertions or deletions could produce amplicons of visibly different sizes than expected, we used direct Sanger sequencing of questionable amplicons to test for presence of the expected HCMV sequence. After amplification of the HCMV genome, all amplicons were quantified on a Nanodrop 1000, pooled in equimolar proportions and used as substrate in Illumina sequencing.
Illumina sequencing
The DNA in pooled amplicons was sheared by sonication on a Sonic Dismembrator 550 (Fisher) until the median size was ∼350 bp. The DNA library was prepared as stated previously [65]. Briefly, DNA was end-repaired using the End-Repair Enzyme Mix (NEB), and A-tailed using the ATP and Klenow (exo-) (NEB). Adapters with appropriate barcodes were ligated onto the modified DNA ends. The library was then size selected on a 2% agarose gel, to produce a library with a median size of 350 bp+/−50 bp. The library was amplified with Illumina primers (P/N 1003454) (www.illumina.com). Once prepared, the libraries were combined in appropriate ratios and submitted for paired-end sequencing on the Illumina GAII. A Toledo strain amplicon set was included as an internal control for measuring error rates.
BAC resequencing and development of methodology
HCMV BAC DNAs of the AD169 and Toledo strains were PCR amplified and processed for sequencing as described above. The barcoded DNAs were then sequenced on a single lane of the Illumina GAII. Output sequences from the Illumina GAII were first converted from Illumina FASTQ format to Sanger standard FASTQ and were then separated based on barcode sequences, which were subsequently trimmed before subsequent processing. The sequences were then aligned to either the AD169 BAC (GenBank # AC146999) or Toledo BAC (GenBank # AC146905) using Novoalign (Novocraft). The alignment data were then ported to MAQ through the Novo2MAQ utility (Novocraft) and downstream analyses were performed with the MAQ software suite [66]. The pileup output from the alignment was then analyzed to call any mismatches between the sequence reads and the reference genome. All mismatches from this output have an associated basecall quality, mapping quality, local depth, number of mismatch occurrences and mismatch frequency. The basecall quality and mapping quality are calculated by the sequencing and alignment software, respectively.
Development of variant filtering algorithm
We used HCMV-BACs as templates for PCR amplification and paired-end sequencing on the Illumina GAII to develop an algorithm that would reduce error. The output was 108 megabases of HCMV sequence or the equivalent of approximately 466 HCMV genomes (Table 1). The data were aligned to the appropriate reference genome using Novoalign and MAQ. Using these data, we developed a variant filtering algorithm. This algorithm has been designed to filter the mismatch output from the alignment stage and aid in sorting “true” variants in the viral population from those mismatches created by PCR or sequencing errors. We produced in silico models of mixed viral populations in which the AD169:Toledo ratio was 1 : 1, 1 : 10, 1 : 100, 1 : 200, and 1 : 1000. Thresholds for minimum basecall quality (≥30), mapping quality (≥89), depth (≥15), mismatch count (≥3) and mismtach frequency (≥0.019) were found to minimize false positives. With these conservative thresholds, we had a detection rate of up to 75%, suggesting that the variants detected in clinical samples will under-represent the true level of variation in the populations. However, the number of false positives was very low in these in silico experiments even when the input minor genome was 1% of the population (Table S1). Modeling of two genotype mixed populations, like those represented in Table S1, illustrates a worst case scenario for a false positive rate. In Table S1, there are two types of variants: “true” variants, sourced from the minor genome type, and errors resulting from PCR or sequencing. The absolute level of true variants will be dependent on the number of minor genome types; as the number of minor genome types increases, the number of true variants also increases. The number of errors, though, is a function of PCR and sequencing and should be independent of the number of minor genome types. Thus, the ratio of errors to true variants (the false positive rate) will decrease as the number of minor genome types increases. In this modeling experiment, there is only one minor genome type and thus, we are recording the upper limit of false positive rates of a mixed genome type population. From the Sanger dataset (Table 4), it was shown that the populations studied are comprised of many genotypes (e.g. 13 unique genotypes from 20 clones), not just one minor genotype. Thus, this modeling experiment overestimates the actual false positive rate of the clinical data.
It was possible that the relatively high G:C content of the HCMV genome could alter error rates across the genome, and should be addressed by the error filtering protocol. However, we did not detect a relationship between error rates and G:C content from the BAC resequencing data (data not shown). We did observe an association between G:C content and depth, with reduced depth at very low (20%) or very high (>80%) G:C content (data not shown). This characteristic of the Illumina platform has been documented previously [67]. We corrected for differences in depth when analyzing the intrahost populations (Figure S5) so that changes in depth associated with G:C content should not alter our analyses.
Performance of quantitative high throughput sequencing
To determine the quantitative capabilities of our methodology, we combined Toledo and AD169 BAC DNA in ratios of 1 : 10 and 1 : 100 as templates for PCR amplification (with Toledo present as the major genome) and then amplified two regions of the genome using our PCR amplification technique. These two regions represent ∼6 kb of the HCMV genome and have a GC content of 58%, approximately equal to the genome wide average of 57%. In these regions, there are 118 sites of mismatch between the Toledo and AD169 genomes. The amplification products were processed and sequenced using the Illumina GAII platform and the output was aligned to the Toledo genome. We ran the data through our variant filtering algorithm to detect the minor variants in the sequence population (i.e. AD169-derived sequence). Our data revealed a 48% detection rate when the minor genome is present as 10% of the PCR template and a 38% detection rate when present as 1% (Table S9). The relatively low detection rate is a consequence of the stringency of the filtering algorithm we developed. The frequency of the minor variants detected in the output sequence was approximately equal to their frequency in the input DNA. These data show that this methodology is suitable for detection and quantitative description of variants in populations.
Calling sample specific genome type of clinical samples
A schematic for calling genome types is shown in Figure S4. The high throughput sequencing reads were initially aligned to Merlin (Ref Seq ID: NC_006273). Output from this initial alignment was used to call variants with frequency >0.5 at every position of the genome because these variants were interpreted to best represent the major allele of the sample. Sites that did not have an allele with a frequency >0.5 were left as uncalled bases (N), and were excluded from intrahost diversity measurements since they represent tri - or quad-allelic sites. The high frequency variants were incorporated into a sample specific genome type. Reads that did not initially align were used as substrate for de novo contiguous sequence (contigs) assembly using SHARCGS [68]. These contigs were then aligned to the sample specific genome type using Geneious [69] and incorporated into the genome if sequence identity was found. Using this strategy, we were able to remove up to ∼1 kb of uncalled bases from the genome type. The sample specific genome type was used in another round of alignment of the sample's sequencing reads. With this strategy, we observed a 1–6% increase in the number of aligned reads after this round as compared to the initial alignment to Merlin. Because more reads aligned, additional high frequency variants were called. The high frequency variants were incorporated into the sample specific genome type and again contigs were aligned to the genome type. This process was repeated until no additional reads aligned between rounds of building the sequence (usually 4 rounds were required). At the end of the process, a single specific genome type was created for each sample, which incorporates all high frequency variants found within. It is unknown if the sample specific genome type represents any single genome within the sample because linkage information is lost from short read sequencing. The sample specific genome type is a computational tool that aids in the alignment of short reads, particularly when a pre-existing reference sequence is unavailable or is divergent from the sample.
Analysis of false positive rate of clinical samples
Variants were called from the clinical sequencing data or BAC resequencing data through filtering with the variant caller algorithm. All alignments used to generate the data were normalized to an average depth of 200 genome equivalents. A depth of 200 was chosen because the lowest depth of an included dataset was ∼200 (i.e., AD169 BAC resequencing), so the ceiling was set to normalize across datasets. Mismatches from BAC resequencing were assumed to be errors and mismatches from clinical sequencing were assumed to be either errors or true variants. Without filtering, BAC resequencing generated, on average, 106,485 called mismatches and clinical sequencing generated 116,594 mismatches (Figures S2A, S2C). Therefore, we estimate a false positive rate in the unfiltered clinical data of 91.3% (106,485 of 116,594). However, filtering with the variant caller reduced estimated false positives to 6.7% of the clinical variants within populations (Figures S2B, S2D).
To determine the error rates of calling interhost polymorphisms (frequency >0.5), a similar analysis of the BAC resequencing data was undertaken. We determined that the error rate for calling polymorphisms is 0.028%, or ∼65 erroneous polymorphisms per genome (Table S2). On average, interhost HCMV sequence data contained >2300 polymorphisms per genome.
It should be noted that the error rate for calling interhost polymorphisms is significantly lower than the error rate for calling intrahost variants (0.028% vs. 6.7%). Intrahost variants must occur at least 3 times as part of the filtering strategy. However, interhost polymorphisms, because they are present at frequency >0.5 and the minimum depth is 15, must occur more than 8 times to be called. Because random errors generated by PCR or sequencing will most likely be rare, the possibility of random errors occurring ≥8 times and occurring in >50% of reads is low. Thus, a lower percentage of errors are included in the interhost polymorphism data then the intrahost variant data.
Measurement of positive selection in intrahost populations
The genome wide intrahost variant data was analyzed using the program SweepFinder (http://people.binf.ku.dk/rasmus/webpage/sf.html), which implements the methods of Nielsen et al. [54] and outputs the position, selection coefficient and composite likelihood ratios (CLRs) of genomic regions. CLRs are measures of the probability of a selective sweep within a genomic region. To determine the significance of the data, 1000 simulations were performed under a standard neutral model using the ms program [70]. A set of simulations was run for each clinical sample population, in which the number of segregating sites and value of θ (Watterson estimator) of the simulation equaled the corresponding values calculated from the clinical samples. The simulation was then processed with SweepFinder, and output from this analysis (Figure S8) was used to determine p values by comparing the clinical value to the simulated outputs.
Clonal Sanger sequencing
ORFs were chosen for clonal Sanger sequence by selecting candidate ORFs from each patient sample that displayed high intrahost variability. All clonally sequenced regions were between 500–700 bp, such that variability data could be generated in a single Sanger sequencing reaction. The regions were amplified with the appropriate primers using the PCR protocol described above, A-tailed with Kleno exo- and dATP (NEB), and cloned into the Strataclone cloning vector (Stratagene). For each ORF, 20 clones were selected at random and sequenced. As a control, a 500 bp region of Toledo-BAC was amplified and clonally sequenced in the same manner. These data were then analyzed in DnaSP [71] to determine nucleotide diversity (π) and genotype distribution.
Statistical analyses
For analysis of the association of ORF function or kinetics with intrahost nucleotide diversity or interhost dN/dS, a 1-factor ANOVA analysis was performed. A Bonferroni correction for multiple testing was carried out, where a significant p-value was considered <.05/K where K is the number of tests run per dataset. A G-test was performed on the interhost dN/dS values with the null hypothesis set as dN/dS = 1. The McDonald-Kreitman test was done using the web portal as described in [72], which performs the analysis using a Jukes-Cantor correction for divergence and the statistical analysis based on a 2×2 contingency table. A neutral model was rejected if p<0.05. A Z-test was used to determine the significance of the proportions of the mean diversity of non-coding and coding variants. The distribution of variant frequencies was analyzed by a two-tailed Mann-Whitney test.
Availability of data
Raw sequencing reads from Illumina sequencing are deposited in the Sequence Read Archive (http://www.ncbi.nlm.nih.gov/Traces/sra/sra.cgi). Major genome types generated from this study are deposited in Genbank (http://www.ncbi.nlm.nih.gov/genbank/index.html).
Supporting Information
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Zdroje
1. DowdJB
AielloAE
AlleyDE
2009 Socioeconomic disparities in the seroprevalence of cytomegalovirus infection in the US population: NHANES III. Epidemiol Infect 137 58 65
2. MurphJR
SouzaIE
DawsonJD
BensonP
PetheramSJ
1998 Epidemiology of Congenital Cytomegalovirus Infection: Maternal Risk Factors and Molecular Analysis of Cytomegalovirus Strains. Am J Epidemiol 147 940 947
3. ArvinAM
FastP
MyersM
PlotkinS
RabinovichR
2004 Vaccine development to prevent cytomegalovirus disease: report from the National Vaccine Advisory Committee. Clin Infect Dis 39 233 239
4. HassanJ
ConnellJ
2007 Translational Mini-Review Series on Infectious Disease:Congenital cytomegalovirus infection: 50 years on. Clin Exp Immunol 149 205 210
5. DolanA
CunninghamC
HectorRD
Hassan-WalkerAF
LeeL
2004 Genetic content of wild-type human cytomegalovirus. J Gen Virol 85 1301 1312
6. DavisonAJ
DolanA
AkterP
AddisonC
DarganDJ
2003 The human cytomegalovirus genome revisited: comparison with the chimpanzee cytomegalovirus genome. J Gen Virol 84 17 28
7. ChaTA
TomE
KembleGW
DukeGM
MocarskiES
1996 Human cytomegalovirus clinical isolates carry at least 19 genes not found in laboratory strains. J Virol 70 78 83
8. PrichardMN
PenfoldME
DukeGM
SpaeteRR
KembleGW
2001 A review of genetic differences between limited and extensively passaged human cytomegalovirus strains. Rev Med Virol 11 191 200
9. HeoJ
PetheramS
DemmlerG
MurphJR
AdlerSP
2008 Polymorphisms within human cytomegalovirus chemokine (UL146/UL147) and cytokine receptor genes (UL144) are not predictive of sequelae in congenitally infected children. Virology 378 86 96
10. JiYH
Rong SunZ
RuanQ
GuoJJ
HeR
2006 Polymorphisms of human cytomegalovirus UL148A, UL148B, UL148C, UL148D genes in clinical strains. J Clin Virol 37 252 257
11. HeR
RuanQ
QiY
MaYP
HuangYJ
2006 Sequence variability of human cytomegalovirus UL143 in low-passage clinical isolates. Chin Med J (Engl) 119 397 402
12. MaYP
RuanQ
HeR
QiY
SunZR
2006 Sequence variability of the human cytomegalovirus UL141 Open Reading Frame in clinical strains. Arch Virol 151 827 835
13. Arav-BogerR
BattagliaCA
LazzarottoT
GabrielliL
ZongJC
2006 Cytomegalovirus (CMV)-encoded UL144 (truncated tumor necrosis factor receptor) and outcome of congenital CMV infection. J Infect Dis 194 464 473
14. Arav-BogerR
FosterCB
ZongJC
PassRF
2006 Human cytomegalovirus-encoded alpha -chemokines exhibit high sequence variability in congenitally infected newborns. J Infect Dis 193 788 791
15. PignatelliS
Dal MonteP
RossiniG
LazzarottoT
GattoMR
2003 Intrauterine cytomegalovirus infection and glycoprotein N (gN) genotypes. J Clin Virol 28 38 43
16. BarM
Shannon-LoweC
GeballeAP
2001 Differentiation of Human Cytomegalovirus Genotypes in Immunocompromised Patients on the Basis of UL4 Gene Polymorphisms. J Infect Dis 183 218 225
17. SekulinK
GorzerI
Heiss-CzedikD
Puchhammer-StocklE
2007 Analysis of the variability of CMV strains in the RL11D domain of the RL11 multigene family. Virus Genes 35 577 583
18. RasmussenL
GeisslerA
CowanC
ChaseA
WintersM
2002 The Genes Encoding the gCIII Complex of Human Cytomegalovirus Exist in Highly Diverse Combinations in Clinical Isolates. J Virol 76 10841 10848
19. ChouS
1992 Comparative analysis of sequence variation in gp116 and gp55 components of glycoprotein B of human cytomegalovirus. Virology 188 388 390
20. PignatelliS
Dal MonteP
LandiniMP
2001 gpUL73 (gN) genomic variants of human cytomegalovirus isolates are clustered into four distinct genotypes. J Gen Virol 82 2777 2784
21. BenedictCA
ButrovichKD
LurainNS
CorbeilJ
RooneyI
1999 Cutting Edge: A Novel Viral TNF Receptor Superfamily Member in Virulent Strains of Human Cytomegalovirus. J Immunol 162 6967 6970
22. PenfoldME
DairaghiDJ
DukeGM
SaederupN
MocarskiES
1999 Cytomegalovirus encodes a potent alpha chemokine. Proc Natl Acad Sci U S A 96 9839 9844
23. YanH
KoyanoS
InamiY
YamamotoY
SuzutaniT
2008 Genetic variations in the gB, UL144 and UL149 genes of human cytomegalovirus strains collected from congenitally and postnatally infected Japanese children. Arch Virol 153 667 674
24. MurayamaT
TakegoshiM
TanumaJ
EizuruY
2005 Analysis of human cytomegalovirus UL144 variability in low-passage clinical isolates in Japan. Intervirology 48 201 206
25. BaleJFJr
PetheramSJ
RobertsonM
MurphJR
DemmlerG
2001 Human cytomegalovirus a sequence and UL144 variability in strains from infected children. J Med Virol 65 90 96
26. HumarA
KumarD
GilbertC
BoivinG
2003 Cytomegalovirus (CMV) Glycoprotein B Genotypes and Response to Antiviral Therapy, in Solid-Organ-Transplant Recipients with CMV Disease. J Infect Dis 188 581 584
27. CoaquetteA
BourgeoisA
DirandC
VarinA
ChenW
2004 Mixed Cytomegalovirus Glycoprotein B Genotypes in Immunocompromised Patients. Clin Infect Dis 39 155 161
28. PeekR
VerbraakF
BruinenbergM
Van der LelijA
Van den HornG
1998 Cytomegalovirus glycoprotein B genotyping in ocular fluids and blood of AIDS patients with cytomegalovirus retinitis. Invest Ophthalmol Vis Sci 39 1183 1187
29. PangX
HumarA
PreiksaitisJK
2008 Concurrent Genotyping and Quantitation of Cytomegalovirus gB Genotypes in Solid-Organ-Transplant Recipients by Use of a Real-Time PCR Assay. J Clin Microbiol 46 4004 4010
30. SarcinellaL
MazzulliT
WilleyB
HumarA
2002 Cytomegalovirus glycoprotein B genotype does not correlate with outcomes in liver transplant patients. J Clin Virol 24 99 105
31. BradleyAJ
KovácsIJ
GathererD
DarganDJ
AlkharsahKR
2008 Genotypic analysis of two hypervariable human cytomegalovirus genes. J Med Virol 80 1615 1623
32. StantonR
WestmorelandD
FoxJD
DavisonAJ
WilkinsonGW
2005 Stability of human cytomegalovirus genotypes in persistently infected renal transplant recipients. J Med Virol 75 42 46
33. GörzerI
KerschnerH
JakschP
BauerC
SeebacherG
2008 Virus load dynamics of individual CMV-genotypes in lung transplant recipients with mixed-genotype infections. J Med Virol 80 1405 1414
34. SowmyaP
MadhavanHN
2009 Analysis of mixed infections by multiple genotypes of human cytomegalovirus in immunocompromised patients. J Med Virol 81 861 869
35. Hassan-WalkerAF
OkwuadiS
LeeL
GriffithsPD
EmeryVC
2004 Sequence variability of the alpha-chemokine UL146 from clinical strains of human cytomegalovirus. J Med Virol 74 573 579
36. Puchhammer-StocklE
GorzerI
ZoufalyA
JakschP
BauerCC
2006 Emergence of multiple cytomegalovirus strains in blood and lung of lung transplant recipients. Transplantation 81 187 194
37. BradleyAJ
KovacsIJ
GathererD
DarganDJ
AlkharsahKR
2008 Genotypic analysis of two hypervariable human cytomegalovirus genes. J Med Virol 80 1615 1623
38. HolzerlandtR
OrengoC
KellamP
AlbaMM
2002 Identification of New Herpesvirus Gene Homologs in the Human Genome. Genome Res 12 1739 1748
39. PedenK
MountsP
HaywardGS
1982 Homology between mammalian cell DNA sequences and human herpesvirus genomes detected by a hybridization procedure with high-complexity probe. Cell 31 71 80
40. MurphyE
YuD
GrimwoodJ
SchmutzJ
DicksonM
2003 Coding potential of laboratory and clinical strains of human cytomegalovirus. Proc Natl Acad Sci U S A 100 14976 14981
41. SimmonsSL
DibartoloG
DenefVJ
GoltsmanDS
ThelenMP
2008 Population genomic analysis of strain variation in Leptospirillum group II bacteria involved in acid mine drainage formation. PLoS Biol 6 e177
42. TysonGW
ChapmanJ
HugenholtzP
AllenEE
RamRJ
2004 Community structure and metabolism through reconstruction of microbial genomes from the environment. Nature 428 37 43
43. MooreJH
2009 From genotypes to genometypes: putting the genome back in genome-wide association studies. Eur J Human Genet 17 1205 1206
44. GörzerI
GuellyC
TrajanoskiS
Puchhammer-StocklE
2010 Deep sequencing reveals highly complex dynamics of human cytomegalovirus genotypes in transplant patients over time. J VirolJ:VI 00475 00410
45. NeiM
LiWH
1979 Mathematical model for studying genetic variation in terms of restriction endonucleases. Proc Natl Acad Sci U S A 76 5269 5273
46. ZhuT
MoH
WangN
NamDS
CaoY
1993 Genotypic and phenotypic characterization of HIV-1 patients with primary infection. Science 261 1179 1181
47. Salazar-GonzalezJF
SalazarMG
KeeleBF
LearnGH
GiorgiEE
2009 Genetic identity, biological phenotype, and evolutionary pathways of transmitted/founder viruses in acute and early HIV-1 infection. J Exp Med 206 1273 1289
48. JerzakG
BernardKA
KramerLD
EbelGD
2005 Genetic variation in West Nile virus from naturally infected mosquitoes and birds suggests quasispecies structure and strong purifying selection. J Gen Virol 86 2175 2183
49. TroeschM
MeunierI
LapierreP
LapointeN
AlvarezF
2006 Study of a novel hypervariable region in hepatitis C virus (HCV) E2 envelope glycoprotein. Virology 352 357 367
50. WangWK
LinSR
LeeCM
KingCC
ChangSC
2002 Dengue type 3 virus in plasma is a population of closely related genomes: quasispecies. J Virol 76 4662 4665
51. HolmesEC
2003 Patterns of Intra - and Interhost Nonsynonymous Variation Reveal Strong Purifying Selection in Dengue Virus. J Virol 77 11296 11298
52. SylwesterAW
MitchellBL
EdgarJB
TaorminaC
PelteC
2005 Broadly targeted human cytomegalovirus-specific CD4+ and CD8+ T cells dominate the memory compartments of exposed subjects. J Exp Med 202 673 685
53. NishiyamaY
MaenoK
YoshidaS
1983 Characterization of human cytomegalovirus-induced DNA polymerase and the associated 3′-to-5′, exonuclease. Virology 124 221 231
54. NielsenR
WilliamsonS
KimY
HubiszMJ
ClarkAG
2005 Genomic scans for selective sweeps using SNP data. Genome Res 15 1566 1575
55. SmithJM
HaighJ
1974 The hitch-hiking effect of a favourable gene. Genet Res 23 23 35
56. KaplanNL
HudsonRR
LangleyCH
1989 The "hitchhiking effect" revisited. Genetics 123 887 899
57. Arav-BogerR
ZongJC
FosterCB
2005 Loss of linkage disequilibrium and accelerated protein divergence in duplicated cytomegalovirus chemokine genes. Virus Genes 31 65 72
58. YanH
KoyanoS
InamiY
YamamotoY
SuzutaniT
2008 Genetic linkage among human cytomegalovirus glycoprotein N (gN) and gO genes, with evidence for recombination from congenitally and post-natally infected Japanese infants. J Gen Virol 89 2275 2279
59. McDonaldJH
KreitmanM
1991 Adaptive protein evolution at the Adh locus in Drosophila. Nature 351 652 654
60. GibsonL
PiccininiG
LilleriD
RevelloMG
WangZ
2004 Human cytomegalovirus proteins pp65 and immediate early protein 1 are common targets for CD8+ T cell responses in children with congenital or postnatal human cytomegalovirus infection. J Immunol 172 2256 2264
61. CunninghamC
GathererD
HilfrichB
BaluchovaK
DarganDJ
2009 Sequences of complete human cytomegalovirus genomes from infected cell cultures and clinical specimens. J Gen Virol 91 605 615
62. SpatzSJ
2010 Accumulation of attenuating mutations in varying proportions within a high passage very virulent plus strain of Gallid herpesvirus type 2. Virus Res 149 135 142
63. YuD
SmithGA
EnquistLW
ShenkT
2002 Construction of a self-excisable bacterial artificial chromosome containing the human cytomegalovirus genome and mutagenesis of the diploid TRL/IRL13 gene. J Virol 76 2316 2328
64. GaultE
MichelY
DeheeA
BelabaniC
NicolasJC
2001 Quantification of human cytomegalovirus DNA by real-time PCR. J Clin Microbiol 39 772 775
65. QuailMA
KozarewaI
SmithF
ScallyA
StephensPJ
2008 A large genome center's improvements to the Illumina sequencing system. Nat Methods 5 1005 1010
66. LiH
RuanJ
DurbinR
2008 Mapping short DNA sequencing reads and calling variants using mapping quality scores. Genome Res 18 1851 1858
67. BentleyDR
BalasubramanianS
SwerdlowHP
SmithGP
MiltonJ
2008 Accurate whole human genome sequencing using reversible terminator chemistry. Nature 456 53 59
68. DohmJC
LottazC
BorodinaT
HimmelbauerH
2007 SHARCGS, a fast and highly accurate short-read assembly algorithm for de novo genomic sequencing. Genome Res 17 1697 1706
69. DrummondAJ
AshtonB
BuxtonS
CheungM
HeledJ
2010 Geneious, version 4.8. Biomatters, Inc Available: http://www.geneious.com
70. HudsonRR
2002 Generating samples under a Wright-Fisher neutral model of genetic variation. Bioinformatics 18 337 338
71. LibradoP
RozasJ
2009 DnaSP v5: a software for comprehensive analysis of DNA polymorphism data. Bioinformatics 25 1451 1452
72. EgeaR
CasillasS
BarbadillaA
2008 Standard and generalized McDonald-Kreitman test: a website to detect selection by comparing different classes of DNA sites. Nucleic Acids Res 36 W157 162
73. NeiM
GojoboriT
1986 Simple methods for estimating the numbers of synonymous and nonsynonymous nucleotide substitutions. Mol Biol Evol 3 418 426
Štítky
Hygiena a epidemiologie Infekční lékařství LaboratořČlánek vyšel v časopise
PLOS Pathogens
2011 Číslo 5
- Farmakovigilanční studie perorálních antivirotik indikovaných v léčbě COVID-19
- Jak souvisí postcovidový syndrom s poškozením mozku?
- Měli bychom postcovidový syndrom léčit antidepresivy?
- 10 bodů k očkování proti COVID-19: stanovisko České společnosti alergologie a klinické imunologie ČLS JEP
Nejčtenější v tomto čísle
- Crystal Structure and Functional Analysis of the SARS-Coronavirus RNA Cap 2′-O-Methyltransferase nsp10/nsp16 Complex
- Lymphoadenopathy during Lyme Borreliosis Is Caused by Spirochete Migration-Induced Specific B Cell Activation
- The OXI1 Kinase Pathway Mediates -Induced Growth Promotion in Arabidopsis
- : An Emerging Cause of Sexually Transmitted Disease in Women