
A Comprehensive Map of Mobile Element Insertion Polymorphisms in Humans
As a consequence of the accumulation of insertion events over evolutionary time, mobile elements now comprise nearly half of the human genome. The Alu, L1, and SVA mobile element families are still duplicating, generating variation between individual genomes. Mobile element insertions (MEI) have been identified as causes for genetic diseases, including hemophilia, neurofibromatosis, and various cancers. Here we present a comprehensive map of 7,380 MEI polymorphisms from the 1000 Genomes Project whole-genome sequencing data of 185 samples in three major populations detected with two detection methods. This catalog enables us to systematically study mutation rates, population segregation, genomic distribution, and functional properties of MEI polymorphisms and to compare MEI to SNP variation from the same individuals. Population allele frequencies of MEI and SNPs are described, broadly, by the same neutral ancestral processes despite vastly different mutation mechanisms and rates, except in coding regions where MEI are virtually absent, presumably due to strong negative selection. A direct comparison of MEI and SNP diversity levels suggests a differential mobile element insertion rate among populations.
Published in the journal:
. PLoS Genet 7(8): e32767. doi:10.1371/journal.pgen.1002236
Category:
Research Article
doi:
https://doi.org/10.1371/journal.pgen.1002236
Summary
As a consequence of the accumulation of insertion events over evolutionary time, mobile elements now comprise nearly half of the human genome. The Alu, L1, and SVA mobile element families are still duplicating, generating variation between individual genomes. Mobile element insertions (MEI) have been identified as causes for genetic diseases, including hemophilia, neurofibromatosis, and various cancers. Here we present a comprehensive map of 7,380 MEI polymorphisms from the 1000 Genomes Project whole-genome sequencing data of 185 samples in three major populations detected with two detection methods. This catalog enables us to systematically study mutation rates, population segregation, genomic distribution, and functional properties of MEI polymorphisms and to compare MEI to SNP variation from the same individuals. Population allele frequencies of MEI and SNPs are described, broadly, by the same neutral ancestral processes despite vastly different mutation mechanisms and rates, except in coding regions where MEI are virtually absent, presumably due to strong negative selection. A direct comparison of MEI and SNP diversity levels suggests a differential mobile element insertion rate among populations.
Introduction
Mobile elements: significance and current catalogs
Retrotransposons are endogenous genomic sequences that copy and paste into locations throughout host genomes [1]–[3]. Most mobile elements annotated in the human reference genome are remnants of ancient retrotransposition events and are no longer capable of active retrotransposition. However, a fraction of mobile elements remain active and contribute to variation between individuals in the human population. These active elements belong almost exclusively to the Alu, L1, and SVA families of non-LTR retrotransposons [4].
The Alu family is the most common mobile element in primate genomes, with more than 1.1 million copies in Homo sapiens [5]–[7]. The sequence of a full-length Alu element is 300 bp long. Alu elements are classified into a range of sub-families which have different propensities for retrotransposition, and are identified according to sequence alterations. Several AluY sub-families are currently active and are responsible for the bulk of mobile element insertion variation in Homo sapiens. The human reference genome contains over 140,000 annotated AluY elements. After Alus, L1 insertions are the next most prevalent family of mobile elements. There are over 500,000 L1 elements annotated in Homo sapiens. A full-length L1 is a sequence of roughly 6 kb in length and the most active L1 sub-family in the human lineage is L1HS [8], [9]. There are a little more than 1,500 L1HS annotated elements in the human reference. A third family of mobile element are SVA retrotransposons [10]. SVAs are hybrid elements of SINE, VNTR and Alu components that range in size up to several Kb, with more than 3,600 annotated SVA elements in the human reference genome. SVA elements are thought to be the youngest family of retrotransposons in primates [11]. Other less common classes of mobile elements, such as DNA transposons, and endogenous retroviruses are not the focus in this study.
Mobile element insertions (MEI) are known to generate significant structural variation within Homo sapiens [12], [13] and have diverse functional impacts [14]–[16]. In vitro experiments identified key features of Alu [17] and L1 [18] elements responsible for retrotransposon activity. The identification of MEI variant loci in humans initially began with disease-causing insertion events (e.g. hemophilia [19], breast cancer [20]). Experimental approaches were based upon library screening and small-scale PCR based display assays [21]. These approaches have been augmented by comparisons of the NCBI and the HuRef genomes [22], [23], large scale fosmid-end sequences [24], and targeted sequencing of element-specific PCR products [25]–[28]. The dbRIP database of MEI polymorphisms [29] currently contains 2,691 polymorphic loci, enabling early estimates for the total number of segregating events [25] and per-generation mutation rates [23].
MEI polymorphisms can be detected either as insertions or as deletions in samples relative to the reference genome. Mechanistically, however, both types of observations are due to retrotransposon insertion; precise excisions of mobile elements are essentially non-existent [1]. Therefore MEI detected as deletions are, in fact, retrotransposon insertions in the reference DNA and can be verified as such by comparison with ancestral genomes. Detection and genotyping properties of MEI detected as insertions (“non-reference MEI”) and as deletions (“reference MEI”) are substantially different. We present their respective properties separately before combining the two detection modes into a unified MEI analysis. The deletion detection methods and properties of the full set of 1000GP deletions have been extensively described in the 1000GP CNV companion paper [30]. This allows us to focus on specific properties of the reference MEI subset of those deletions. Effective computational algorithms using second-generation sequencing data exist for identifying deletions [27], [31], [32], and have been used to find MEI in particular [33]. Detecting non-reference MEI directly as insertions from whole genome shotgun sequence data poses a more challenging problem, owing to the inherent difficulties associated with accurate mapping of sequenced reads derived from highly repetitive regions of the genome. Only recently have methods been developed for the purpose of non-reference MEI detection from second-generation whole genome shotgun data including published studies of L1 element insertions [34] and of Alu insertions [35]. These studies adopted similar computational approaches to one of our insertion detection methods (the read pair method, see Materials and Methods) and have different detection properties (Text S2 Comparisons, Figures S8, S9, S10).
Relative to previous studies, we present a broad analysis of MEI variation in the human population; with more variant loci detected, from the three major mobile element families, using multiple detection methods, each with comprehensive experimental validation (Table 1). The present study represents the combined efforts of the MEI sub-group of the 1000 Genomes Project and has been prepared as a companion to previous 1000GP pilot publications [30], [36]. The MEI analyzed in this study were included the 1000GP variant call release of July 2010 (ftp://ftp-trace.ncbi.nih.gov/1000genomes/ftp/pilot_data/release/2010_07), also provided as Table S1). The specific purpose here is to provide a more detailed description of the methods, validation experiments, and properties of the 1000GP catalog of MEI events, and to extend the analysis by adding genotype information, population allele frequencies, and population specific mutation rates.

Results
Datasets analyzed
We analyzed two whole-genome datasets produced by the 1000GP, the low coverage pilot dataset consisting of 179 individuals sequenced to ∼1–3X coverage and the trio pilot dataset consisting of two family trios sequenced to high, ∼15–40X coverage (Table S2, Figure S4). These datasets included samples from three continental population groups, 60 samples of European origin (CEU), 59 African (YRI), and 60 Asian samples from Japan and China (CHBJPT). The two pilot datasets were produced and analyzed for complementary purposes. The trio dataset was used for assessing detection methods in high coverage samples and for the purpose of finding candidate de novo insertions in the trio children. The high coverage dataset was used to assess population properties of MEI. Both datasets contributed to the overall catalog of events.
Detection of non-reference mobile element insertions
We developed two complementary methods for the detection of non-reference MEI, a read-pair constraint (RP) method applied to Illumina paired-end short read data, and a split-read (SR) method applied to the longer read data from Roche/454 pyrosequencing (Materials and Methods: non-reference MEI detection). Figure 1a and 1b shows the respective detection signatures and examples of event displays. Candidate MEI events were formed as clusters of supporting fragments. A limitation specific to RP detection arises from annotated elements within a characteristic read pair fragment length of candidate MEI (Figure 1a). Read pairs spanning from a uniquely mapped anchor into an annotated mobile element with a fragment length consistent with the given library fragment length distribution (Figure S5) are characteristic of the reference allele and are not evidence for non-reference MEI. These “background” read pairs occasionally have fragment lengths on the extreme tails of the library distribution and can potentially be misclassified as evidence for non-reference MEI. For this reason RP detection criteria required at least two supporting fragments spanning into the insertions from both sides of the insertion. We also masked insertion positions within a fragment length around each annotated element of the corresponding family from RP detection in order to achieve a low false detection rate. The SR method was not dependent on the fragment length distribution in the 454 data so these additional detection criteria were not required.

We applied the two methods to both 1000GP pilot datasets (Table 1) separately, yielding a total of 5,370 distinct genomic MEI loci, 33% of which were found by both SR and RP methods (Figure 1c). The overall level of detection overlap between SR and RP methods is limited by detection sensitivity and specificity (see below) and the number of samples sequenced by both 454 and by Illumina read pairs.
Detection of reference MEI
In addition to the 5,370 non-reference MEI, we identified 2,010 reference MEI detected as deletions of mobile elements in samples. The reference MEI events were selected from the full release set of 1000GP pilot deletions (n = 22025) [30], [36] based on matching deletion coordinates to RepeatMasker 3.27 Alu, L1, and SVA annotations [6], and the requirement that the mobile element is absent in the chimpanzee genome [37] (6x pan Trogodytes-2.1 assembly) at the corresponding positions in hg18 (Materials and Methods: Reference MEI selection). Figure 1e shows an example event display of an AluYb8 reference MEI, detected as a deletion in the trio pilot data. All but one of the reference MEI were found by one or more of the RP or SR deletion detection algorithms that were part of the released 1000GP deletion call set [30], [38]–[42] with a small overlapping contribution from algorithms based on assembly or read depth methods [43], [44] (Figure 1d, Table S3).
Combined MEI catalog
The complete set of 7,310 MEI calls is simply the combined set of reference and non-reference MEI over both pilot datasets (summarized in Table 1, complete list in Table S1). Insertions occurring at the same locus from different call sets were merged using a 100 bp window for matching positions, choosing the SR insertion coordinate when available to represent the merged event. Similarly for reference MEI, deletion merging was accomplished among the 23 separate 1000GP call sets using a precision-aware algorithm described in detail in the 1000GP SV companion paper [30]. The full catalog of MEI loci appear to be distributed randomly across the genome (Figure 2b) with a characteristic spacing of 0.4 Mb between MEI loci, except for an apparent MEI hotspot in the HLA region of chromosome 6 where 19 MEI loci are clustered in a 1 Mb region (8 times the genomic average density for MEI, Figure S11). Accurate read mapping in the HLA region is complicated by a high density of variation [36], however, we see no evidence of falsely detected MEI here. The balance between reference and non-reference MEI, proportions of RP and SR detected loci, the fraction of previously identified MEI loci, and the validation rate are all consistent with genomic averages; only the density of MEI is significantly increased.
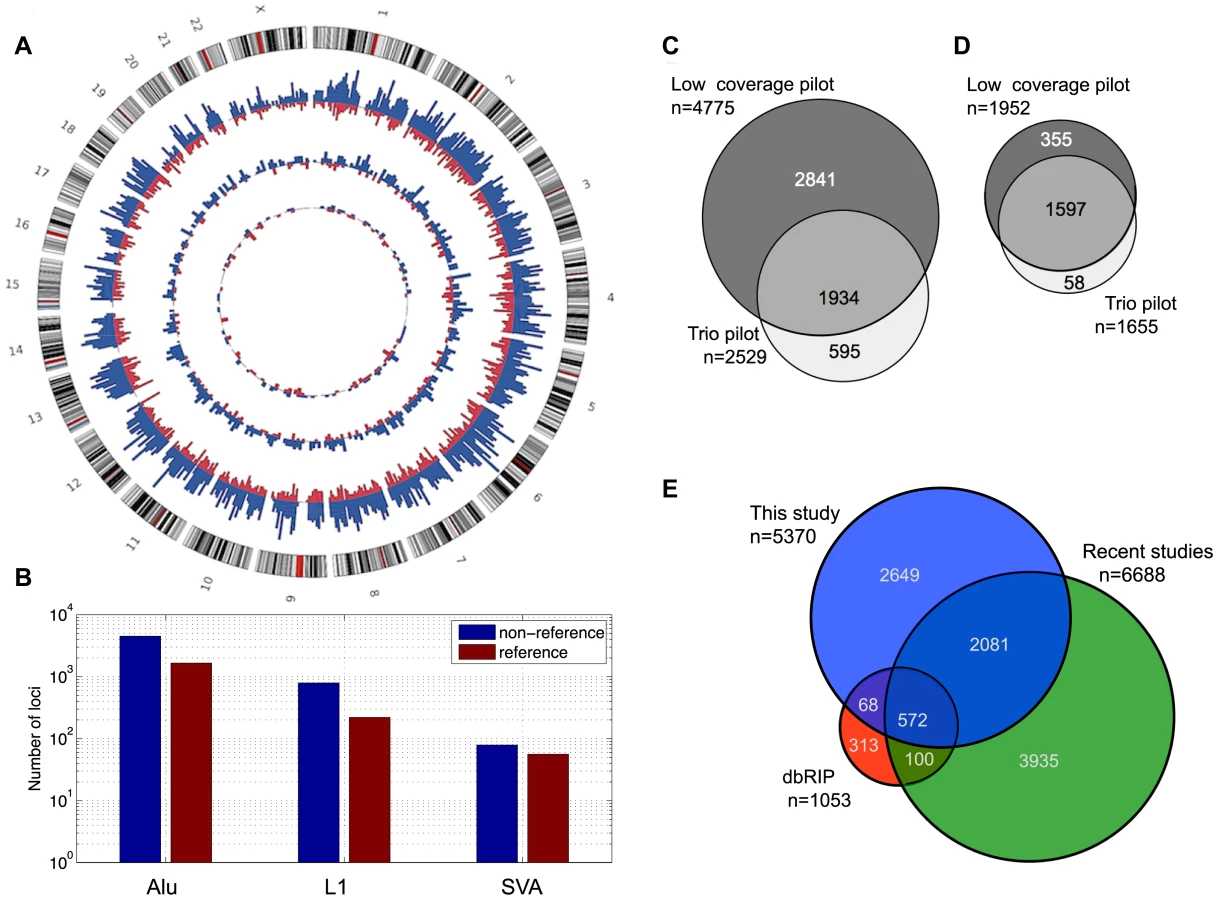
The genomic proportions of the three mobile element families are 85±2% Alu, 12±2% L1, and 2.5±1% SVA (Figure 2b) for both reference and non-reference MEI. Most non-reference MEI loci were detected from the low coverage pilot data (Figure 2c) while the reference MEI were more evenly distributed between the low coverage and trio pilot data (Figure 2d). As described in the 1000GP main pilot paper [36], more than 80% of the non-reference MEI were newly identified loci not detected by previous studies [23]–[28], [34], [35], [45]. However, in the mean time, several published studies have produced new lists of non-reference MEI loci including L1 insertions [34] and Alu insertions [28], [35]. Half of the non-reference MEI loci from this study have not yet been reported elsewhere (Figure 2e, Figure S8). Table 1 of the 1000GP paper lists 5,371 MEI, two of these events were subsequently merged into one to form the present count of 5,370 MEI detected as insertions. For reference MEI, we find that 76% of our events matched deletion coordinates listed in the dbVAR (28 January 2011) structural variation database or a deletion identified in the HuRef genome [22], [46], leaving 24% of the reference MEI unreported prior to 1000GP publications.
The 1000GP catalog of MEI variant sites includes all 7,310 detected loci, including those matching MEI from other publications. Further comparisons among the recent MEI studies are provided in Text S2.
Detection specificity and sensitivity
We benchmarked each of the four non-reference MEI call sets (separate SR and RP call sets for the low coverage and trio pilot datasets) to assess detection sensitivity and specificity. As MEI are currently not suitable for microarray validation due to their highly repetitive sequence, all validations were done by locus-specific PCR. 200 loci were randomly selected from each of the four insertion call sets. Using an automated pipeline [32], primer design was possible for 746 loci (Table S4). In addition to the randomly selected loci, other candidate loci were selected for validation experiments in order to confirm SVA insertions (n = 7), to test potential de novo insertions from the pilot 2 trio (n = 1), and gene-interrupting events (n = 86 attempted), as well as for algorithm training and testing purposes (n = 386). These additional PCR results (Table S4a) were not used to assess false detection rates, except for the special case of SVA insertions, which were under-represented in the random loci selection since SVA insertions are relatively rare.
All candidate loci with successful primer design were tested on two different population genetic panels (Materials and Methods: Validation) one with DNA of 25 individuals from the low coverage pilot, and one with DNA from all samples of the trio pilot dataset. In addition to other human samples from populations not represented by the pilot datasets, DNA of a chimpanzee was also included on the panel to confirm that the identified insertion is indeed human-specific. An example of typical results for a low coverage locus is shown in Figure 3a. Through additional primer design for loci with inconclusive results and PCRs using a primer residing within the 3′ end of a retrotransposon, in particular within SVA elements, more than 98% of the tested candidate loci were successfully genotyped. The validation experiments revealed overall insertion false discovery rates for each dataset of less than 5% (Table 1). Among the different retrotransposon families (L1, SVA, and Alu elements), false discovery rates varied noticeably (Figure 3b), with Alu insertions showing the lowest false-positive rate (2.0 [1.1–3.4] %, followed by L1s (17 [10]–[27] %), and SVAs (27 [8]–[55] %) with 95% confidence intervals. This is not entirely unexpected as polymorphic Alu insertions tend to be low divergence full-length AluY elements, unlike L1 or SVA insertions which tend to be truncated and may be accompanied by adjacent transduced genomic DNA sequences. Although the SR and RP detection methods are very different, the overall detection specificities were remarkably consistent.

Following the validation of non-reference MEI, we assessed detection sensitivity. The primary challenge here was to find suitable gold standard non-reference MEI that should be present in our samples from which to assess sensitivity. We estimated sensitivity in three different ways, as a consistency check. First, we estimated sensitivity by using the high quality non-reference MEI from HuRef [23] as a gold standard and found that 74% of the 650 Alu, L1, or SVA insertions in HuRef matched MEI insertion loci in our catalog (Table S5). This represents a lower limit for insertion detection sensitivity since not all MEI in the HuRef genome are necessarily present in the 1000GP pilot samples. Next we looked at the overlapping insertion detection between the RP and SR methods in the trio children samples (Figure 3c, Figure S6), which were the samples sequenced to the highest depth for both Illumina and 454 data. Based on the detected loci overlap (see Materials and Methods: Detection sensitivity), we estimate 67%±3% and 70%±7% sensitivities respectively for RP and SR insertion detection in the trio children (Table S6), with a combined SR+RP detection sensitivity exceeding 90% in the CEU trio child (see Materials and Methods, Eq. 4) with high coverage data from both 454 and Illumina reads.
A third approach to estimate for the non-reference MEI detection sensitivity is based on the validation PCR genotypes in the low coverage dataset. Since the PCR loci were selected as random subsets for each RP and SR call set independently, the validated sites selected from SR events can be used as a gold standard to assess RP detection sensitivity, and vice-versa. Detection sensitivity as a function of allele frequency (Figure 3d) was estimated for each method from PCR genotypes at those loci randomly selected for validation of the complementary method. PCR genotypes provided the allele frequency estimate on the abscissa. Statistical errors at high allele frequency are large because the limited number of tested MEI loci at higher allele frequencies. Detection sensitivity of the RP method saturates close to 70% at high coverage and the SR method sensitivity exceeds 70% at high coverage (Figure S6). The corresponding trend is apparent in Figure 3d. The combined detection sensitivity approaches 90% for common alleles (Materials and Methods, Eq. 4). However, since relatively few of the low coverage samples were sequenced with 454, a realistic estimate for the detection sensitivity to common MEI insertions is between 70% and 80%. This is consistent with 75% derived from the HuRef gold standard comparison and the sensitivity estimate from the trio pilot overlaps. Equivalent estimates for Alu, L1, and SVA specific sensitivities for common MEI alleles are 75%±10%, 50%±10%, and 50%±20% respectively (Table S9).
Regarding reference MEI detected as deletions, the overall validation rate from PCR and local assembly for the MEI component of deletions was 96%. This does not imply that the remaining 4% were false, only that the released set of deletions contained reference MEI detected by two high specificity algorithms with characteristic false detection rates less than 10%. These algorithms did not require additional validation evidence in the 1000GP release. A rough estimate for the false detection rate for the MEI component of deletions is therefore 0.4%. The number of algorithms supporting a given call is another indicator of call quality. The average number of separate deletion calls (out of a maximum of 23 call sets) supporting events in the MEI subset was 7.8 while the average over all other deletions was 2.3 (Figure S2). The high validation rate and high consensus among detection algorithms indicate that this subset of deletions is relatively free of detection artifact. The practical limitation on the specificity of these events as reference MEI is the subsequent MEI selection criteria. Only a small fraction the 2,010 selected events were ambiguous in terms of matching coordinates to an annotated mobile element with corresponding gap in the chimpanzee genome assembly (e.g. Figure S3, bottom panel). The 1000GP CNV paper identified 2029 reference MEI variants using the BreakSeq algorithm. Overlap between the respective lists is 89%. We estimate 10% as an upper limit on the false discovery rate for reference MEI.
Detection sensitivity for reference MEI was estimated from the fractions of gold standard reference MEI identified by Xing et al. from HuRef [22], [23], [46], and reference MEI identified by Mills et al. [4], [47] from 1000GP samples NA12878 and NA12156 matched to any of our 2,010 reference MEI (Table S5). In each case the fraction of those MEI deletions found in this study exceeded 90%. This level of detection sensitivity is considerably higher than the bulk deletion detection sensitivity reported in the SV companion paper [30], indicating that the RP and SR deletion detection methods developed for the 1000GP were particularly well suited for reference MEI detection.
MEI properties, assembly, and sub-family classification
We characterized each detected MEI event (Table S1) by the insertion position, which algorithm(s) detected the event, number of fragments supporting the insertion and reference alleles, insertion length (Figure S12), element family, bracketing homology (Figure 4a), and assembled sequence. MEI have a characteristic “target site duplication” region of homology bracketing the insertion. The target site duplication length distributions for the MEI detected by different methods, as well as for different element families, peaked at 15 bp with a standard deviation of 7 bp (Figure 4a). The full insertion sequence from reference MEI is readily extracted from the reference, but non-reference MEI require local de novo assembly to reconstruct the inserted sequence. For this we used 454 data to reconstruct 1,105 Alu insertions (Tables S1 and S7) from our event list based on the PHRAP assembly program [48]. We then used BLAT [49] to map assembled contigs back to the build 36.3 human reference to identify the boundaries of the inserted sequence. The inserted sequence was then mapped back to the RepeatMasker mobile element sequences using the RepeatMasker web server (http://www.repeatmasker.org) to identify the sub-family (Figure 4b). The accuracy of Alu sub-family classification was assessed by comparison to matched 359 Alu insertions from dbRIP [29] and nine fully sequenced Alu insertions from PCR validation experiments. 272 of the assembled Alu sub-family classes were identical (74%). The most active Alu sub-families are AluYa5 and AluYb8. AluY sub-families account for essentially all Alu variation. The relative proportions among Alu sub-families are consistent among reference and non-reference MEI, as well as consistent with the Alu sub-families observed in HuRef [23]. The Alu sub-family breakdown differs from that reported by Hormozdiari et. al. [35] who identified more than 10% of their set of insertions from AluJ or AluS sub-families. The authors of that study point out that these ‘older’ Alu events could arise from mechanisms other than retrotransposon insertions.

Genotyping
Genotyping of non-reference MEI (Materials and Methods: Genotyping) was based on counts of fragments supporting the reference allele and fragments supporting the insertion allele at each locus for each sample. Heterozygous MEI sites are identified by roughly equal amounts of reference and alternate allele supporting fragments spanning an insertion locus, while homozygous sites should have all fragments supporting one or the other allele. For reference MEI, we used genotypes produced by the Genome STRiP package [39], which was developed for 1000GP deletion genotyping [30], [39] and incorporates Beagle [50] imputation based on linkage with local SNPs. Both genotyping methods provide phred-scaled [51] genotype quality (GQ) metrics at each site that reflect confidence in the given call based on supporting evidence, GQ = 0 to a total lack of genotype evidence and GQ = 10 indicating that the genotype should be 90% accurate. The GQ metric depends on the number of fragments found to support the MEI and non-MEI alleles for a given locus and sample (Text S2: Genotyping methods). As in most issues of sensitivity vs. specificity, there is a trade-off between high genotype efficiency and genotyping accuracy. The drop-off in genotyping efficiency vs. GQ threshold is more severe for non-reference MEI (Figure S13). For subsequent genotype-based analysis of non-reference MEI sites and samples we required GQ≥7, which corresponds to roughly 40% genotyping efficiency in the low coverage pilot data. For reference MEI we required GQ≥10, which corresponds to an efficiency of 80%. Genotyping efficiency improves with increased sample read coverage (Figure S13, bottom panel), particularly for non-reference MEI.
Genotyping accuracy for non-reference MEI is assessed by direct comparison to PCR validation genotypes in the same samples, and by testing for Mendelian errors in the trios and violations of Hardy-Weinberg Equilibrium in the low coverage data (Text S2 Genotyping tests, Figures S13 and S14). Validation genotypes are listed in Table S4 (also as the “VG” field of the released MEI insertion genotyped VCF files). Genotype contingency tables for the low coverage data (Table 3) show an 87% agreement between sequenced genotypes and PCR genotypes for sites with GQ≥7. Genotyping accuracy improves with increasing GQ threshold (Figure S13) but never exceeds 90% in the low coverage data. Non-reference MEI genotyping performance for high coverage trio data (Table 3, Table S8) was considerably better than for the low coverage data. However, for population analyses we used only low coverage data in order to minimize the potential for coverage biases. The accuracy of GenomeSTRiP genotypes (for reference MEI events) with GQ≥10 was estimated at 99% in the full 1000GP deletion call set [30], [36], [39].
Population segregation of MEI
We estimated MEI allele frequencies from the count of high quality (GQ≥7 non-reference and GQ≥10 for reference MEI) genotyped insertion alleles for each MEI locus. Allele frequencies were estimated from loci with at least 25 high quality genotypes for each continental population group. The two MEI detection modes (i.e. reference and non-reference insertions) have very different allele frequency spectra (Figure 5a–5c). Since the non-reference MEI and reference MEI components have very different powers of detection and genotyping, the two components were corrected separately (Materials and Methods: Allele frequency spectra) before being combined into the full MEI spectrum (Figure 5d–5f). We estimated correction factors for each population group, each element type, and each detection mode (Table S9). Non-reference MEI correction factors are larger than reference MEI factors because of the lower detection sensitivity and genotyping efficiency.

The allele count spectra were compared to the standard neutral model [52]–[54], θ/i, where θ is an MEI diversity parameter and i is the allele count in a fixed number of samples. The value of θ is fit from the MEI allele count spectrum for each population group and the fitted model is the gray dotted line appearing in Figure 5d–5f. Only allele count bins in the range 0.15<frequency<0.95 were used in the fit (bins marked with error bars in Figure 5d–5f) to avoid regions of poor detection sensitivity. The corresponding gray dashed lines superimposed on Figures 5a–5c also represent the neutral model expectation, modified to account for the respective ascertainment conditions, (θ/2N) for reference MEI, (θ/i)(2N−i)/(2N) for non-reference MEI, where N = 25 is the number of samples in the spectra. These ascertainment condition expressions are based on the assumption that the reference genome represents a random sample from the given population, which is admittedly simplistic but nevertheless explains much of the difference between the allele spectra of reference and non-reference MEI. A coalescent simulation (Text S2 Coalescent, Figure S17) for MEI variation also shows this behavior using standard population history parameters [55]. Fitted values of the diversity parameter θ for each of three population groups and each element family are listed in Table 4, along with rough estimates for the corresponding MEI mutation rates based on the neutral model (μ = θ/(4·Ne)) with an effective population size Ne of 10,000 [56], [57]. Confidence intervals for μ and θ (Table 4) take into account Poisson noise and uncertainties in the correction factors, but do not reflect the degree to which the model assumptions are valid.
All three element families have been combined into the allele count spectra shown in Figure 5, although the Alu family is the dominant component. Allele frequency spectra for different element families have similar shapes (Figure 6a). We know from SNP studies that the shape of the allele frequency spectrum is modulated by demographic history, and that this shape is characteristically different for European, African, and Asian populations [56], [57]. When compared to SNP allele frequency spectra from the same datasets (Figure 6b), the MEI and SNP frequency spectra show similar trends among the corresponding populations. Among the three population groups, the CHBJPT spectrum shows relatively few low frequency allele loci. This was also apparent in comparison with the neutral model (Figure 5e).

We also analyzed population differentiation by applying principal component analysis to the matrix of allele counts across the low coverage pilot samples and loci (Figures S15 and S16). Some structure is immediately apparent in the matrix of allele counts, e.g. increased heterozygosity in the YRI samples, but PCA reveals population specific patterns of MEI that result in tight clusters of samples according to geographic origin (Figure 6c); again similar to population patterns for SNPs [58], CNVs [59] and deletions [30].
Functional properties
As few as 39 of the 5,370 non-reference MEI loci were located in exonic sequence, mostly in untranslated regions, and only 3 were found in coding exons (Table 2). These numbers are much lower than expected from random placement (Materials and Methods: Functional calculation), indicating strong selection against MEI disrupting gene function. The suppression factor for an MEI to occur in a coding region compared to the genome-averaged rate is 46x, a much stronger suppression than is observed for coding SNPs (Table S10, suppression factor = 3.9x), and is similar to SNPs that cause the loss of a stop codon (42x, derived from Table 2 of [36]). Two of the MEI interrupting coding regions were PCR-validated. These two MEI appear to be of little functional consequence: ZNF404 is a member of a highly paralogous zinc finger gene family and C14orf166B is a predicted gene without functional annotation. These findings suggest very strong negative selection against MEI interrupting coding regions. Although it is obvious from first principles that insertions in functional regions should be deleterious, the observed suppression factor in a large catalog of MEI in populations quantifies the effect.


Number of ME polymorphisms between pairs of individuals
The high-coverage trio data allows for the most precise estimates of the total number of MEI variants between pairs of individuals because of the high detection sensitivity. The number of pair-wise variant loci is calculated as the presence or absence of an insertion at a given locus, combining reference and non-reference MEI. We selected the two trio children (NA12878 and NA19240) for comparison between CEU and YRI individuals and the trio parents for comparison of individuals within the CEU and the YRI population groups. After corrections for detection sensitivity and false detection (Text S2 and Table S6), we found 2,034±120 MEI variant loci between the African and the European trio children, 1,442±120 between the YRI parents, and 663±140 MEI between the CEU parents. The pair-wise event numbers scale linearly with coalescent time derived from SNPs (Figure 6d) in these samples (Text S2: Coalescent [60]–[64]).
Search for de novo MEI
Previous estimates for the de novo mobile element insertion rate and our own estimate of the MEI mutation rate are one event per 20 births in the human population [23]. Accordingly, we did not expect to find de novo insertions in our sample of two trio children. Among all MEI events detected in the trio offspring against the reference (1,778 in NA12878 and 1,971 in NA19240), we did identify a single de novo candidate insertion in NA12878, not detected in either parent or in any other sample (Table S6, de Novo). A subsequent PCR validation experiment revealed that this insertion was, in fact, present in one of the trio parents, but not detected from the sequence data. All in all, our study found no direct evidence for de novo MEI events in the two trio samples.
MEI heterozygosity and mutation rates
MEI genotyping allows us to estimate MEI heterozygosity within each sample. We define heterozygosity as the count of heterozygous loci across the individual's genome. In a manner similar to the allele frequency analysis, heterozygosity is corrected for detection and genotyping efficiencies (Materials and Methods: Heterozygosity) such that it represents the true number of heterozygous loci in the sample. Heterozygosity, π, and the diversity parameter, θ, fit from the allele count spectrum, are related population metrics that depend on the MEI mutation rate, μMEI, and demographic history. In the neutral model (under mutation-drift equilibrium in the limit of infinite segregating sites and a constant effective population size, Ne) the two metrics should be approximately equal [65]:(1)Deviations can be interpreted as evidence for selection pressure, changing demographic parameters, or possibly as changes in the mutation rates. These metrics were originally developed as a framework for SNP analysis but can also be applied to MEI variants. It is this property of heterozygosity that we wish to exploit. A comparison MEI and SNP heterozygosity within the same samples allows a direct comparison of the corresponding mutation rates, because the impact of long-term demography (here simplified in terms of Ne) is identical for both variant types. Consequently, the MEI mutation rate can be estimated as:(2)Given constant mutation rates we would expect proportionality between πSNP and πMEI in samples from different population groups, however a scatter plot of πMEI vs. πSNP over the low coverage pilot samples (Figure 7a) shows some deviation. Heterozygosity for the Asian sample group is systematically elevated above the proportionality line (dashed line). Also shown on the scatter plot is a grey region corresponding to SNP and MEI differences between the human and chimpanzee reference genomes [37], [66]. The MEI insertion rate is known to be roughly 2.5 times higher in the human than in the chimpanzee lineage [66], however, the time dependence of the MEI mutation rate during human evolution is not yet known. For this, we re-expressed the SNP and MEI heterozygosities for each sample in terms of μMEI vs. coalescent time (Figure 7b) based on equation (2), a constant SNP mutation rate (μSNP∼1.8×10−8 mutations per site per generation [67]), and the coalescent time estimated from the SNP heterozygosity. Characteristic MEI mutation rates for each population group were derived from Eq. (2) with <πMEI> and <πSNP> averaged over the samples in the group. Values of μMEI for each population and each element family are compared to μMEI derived from θ fitting (Figure 7c) and are listed in Table 4 with 95% statistical confidence intervals. Confidence intervals from the allele frequency fits (error bars in Figure 7c) are larger than statistical errors from the averaged heterozygosities over samples (error bars within the circles on Figure 7c) because each sample provided independent observations for the average heterozygosity, whereas in the allele frequency spectra fits all samples were combined. Both estimates are subject to systematic errors that may arise from the detection, genotyping, and correction procedures. To test for systematic biases in μMEI we re-processed both allele frequency spectra and heterozygosity estimates over a range of genotype selection thresholds (Text S2: Stability, Figure S18) and found consistent trends in μMEI among the population groups and element families, although the overall scales of the mutation rates are uncertain to 20%. Values of the element specific mutation rates in Table 4 and Figure 7c are consistent with previous reports [23], [25], [68]. In summary, careful error analysis led us to believe that the differences in the mutation rate observed between the different population sample groups are likely to result from biological processes, rather than measurement or analytical artifacts.


Discussion
Common MEI polymorphisms in the human population
MEI alleles propagate within population groups much like other predominantly neutral polymorphisms. MEI allele frequency spectra from the low coverage samples are in general agreement with expectations from the standard neutral model for allele drift in a population. The major differences in allele frequency spectra between non-reference and reference MEI (Figure 5a–5c) are explained by the ascertainment condition that the derived MEI allele occurs in a given sample (the reference) and are in agreement with expectations based on a coalescent simulation of MEI population drift (Figure S17). MEI allele frequency spectra among the three population groups exhibits a similar trend to SNPs (Figure 6b), although the MEI spectrum in the Asian samples is a poor fit to the θ/i form (χ2/d.f.∼2 from Table 4) with an excess of high frequency alleles and a deficit at low frequency (Figure 5e).
MEI allele frequencies were based on MEI detected and genotyped across three element families (Alu, L1, and SVA), from both non-reference and reference MEI, and multiple detection methods (RP and SR), each with characteristic detection sensitivities and false detection rates. Corrections for these effects, as well as genotyping efficiencies, were included in the allele frequency spectra.
Measurements of MEI heterozygosity offer a more direct method to estimate MEI insertion rates. Like the allele frequency spectrum, heterozygosity is dependent on accurate genotyping and includes corrections for efficiency losses, but in this case the corrections were made on a per sample basis, which is more specific since sample coverage is the dominant limitation for detection and genotyping power (Figure S6). The heterozygosity measurement also has an advantage in that each sample is an independent estimate of the population average <πMEI> and <πSNP>. The heterozygosity measurements revealed evidence for differential MEI mutation rates among the three population groups. The probability that the Asian population samples have the same MEI mutation rate as the other two population groups is very low (paired t-test p-value<10−6). We tested the stability of this result by varying the genotype selection criteria across a range of threshold (Figure S18) and found that the differential MEI rate effect is indeed stable. Sequence coverage in the 1000GP low-coverage pilot data was roughly the same for all three continental population groups (Table S2), so we do not expect coverage differences to generate significant systematic biases in these population comparisons.
The question remains whether the differential MEI mutation rate between populations is driven by a shared increase of μMEI within Homo sapiens, as suggested by Figure 7b, or simply by varying insertion rates among different populations. The pilot data is consistent with either interpretation, so data from more populations (more than 30 population groups from five continents are planned for the full 1000GP) will be needed to discriminate between the two hypotheses.
Based on the global values for the diversity parameters θMEI and πMEI (Table 4), and the neutral model, our rough estimate of the total number of MEI segregating sites in the human population with allele frequency>10% is 4500, and 9000 for frequency>1%, with 20% uncertainty arising from parameter estimates. Counting only those sites with a sufficient number of genotypes to measure allele frequency, our dataset contains more than half of the segregating human MEI sites with frequency>10%.
Significance
This study of the 1000GP pilot datasets is a sizable step toward a complete population-based catalog of common human MEI polymorphisms, made possible by targeting both non-reference and reference MEI events in the human genome. We identified 7,380 polymorphic mobile element insertions from the Alu, L1, and SVA families. Based on experimental validation of random subsets of loci we estimate that the false discovery rate in this study is less than 5%. Detection power for common alleles (allele frequency>10%) varies between non-reference MEI (70%–80%) and reference MEI (>90%). We were also able to assemble the inserted sequence for more than 1,000 non-reference Alu MEI and found consistent proportions of Alu sub-families in comparison to MEI identified in HuRef.
This comprehensive variant discovery and genotyping effort allowed us to directly compare the segregation properties of different variant types from the same dataset. Our analysis revealed that, to a first approximation, the evolution of MEI variants is similar to SNPs and consistent with neutral models [52], [53], except in exonic regions where they are subject to negative selection on the scale that acts against SNP variants resulting in stop codon loss. An intriguing finding from our data, however, is the detection of signals suggesting a recent increase in MEI rates in humans.
Materials and Methods
Non-reference MEI detection
Both the SR and the RP methods were based on identification of non-reference MEI as clusters of mapped DNA fragments in which one end mapped to the consensus sequence of a mobile element while the other end was uniquely mapped to the reference genome in a location inconsistent with a known mobile element location in the reference (Figure 1a–1b). The RP method required at least two MEI supporting fragments across both the 5′ and 3′ insertion breakpoints for each candidate MEI from the pooled datasets (the low coverage and trio pilot data were pooled separately). The SR method required only one MEI supporting fragment across either the 5′ or 3′ breakpoints for candidate events. We used 52 consensus element sequences from Repbase [69] (www.girinst.org, version 14.03, Table S11) to identify reads mapping to mobile elements. The RP method used Mosaik [70] (bioinformatics.bc.edu/marthlab/Mosaik, version 0.9.1176) for read pair mapping of Illumina paired-end data to the NCBI36 human reference (build 36.3) and the Spanner [40] program to identify non-reference MEI by clustering supporting fragments [40], [71], [72]. The SR method also used Mosaik to align 454 data, for full read mapping as well as for split-read mapping. We used extensive simulation experiments [73] to optimize detection methods, algorithm parameters, and post-process MEI candidate event selection filters (further details are provided in Text S2).
Reference MEI selection
The 2,010 reference MEI events are a subset of the 1000GP pilot release of 22,025 deletions [30]. 95% of the MEI sites detected as deletions were found by more than one algorithm but the dominant mapping algorithms were Mosaik, and Maq [74], with detection algorithms Spanner, Pindel [41], BreakDancer [38], and GenomeSTRiP [39]. Two selection criteria ensure that a given deletion corresponds to a true variant MEI inser a given deletion corresponds to a true variant MEI inserted in the reference genome:
-
The deletion coordinates match to an annotated Alu, L1, or SVA element [6] in the hg18 reference, defined as >50% reciprocal overlap and the start and end coordinates both match within a window of 20 bp for Alus, or 200 bp for L1s and SVAs.
-
At least 75% of the deleted region corresponds to a gap in the chimpanzee genome assembly [37].
MEI event matching between algorithms and studies
Non-reference MEI detected by the SR and RP methods were merged according to a 100 bp matching window around the leftmost insertion coordinates. To assess call set intersections between this study and other published lists of non-reference MEI, we used a matching window of 200 bp around each insertion position. We adopted the ‘leftmost’ coordinate convention (Figure S1), in keeping with 1000GP call sets, whereas other studies used rightmost or unclear coordinate conventions. The respective scales of the matching windows were dictated by the characteristic position resolutions of the algorithms (Figure S7, Figure S10), which varied considerably from study to study. Redundant loci from recent publications were not counted multiple times in Figure 2e. To identify matching reference MEI to other studies we required at least 50% reciprocal overlap between the starting and ending NCBI36 deletion coordinates.
Calculations of sample sequence coverage
For SR detection the relevant coverage statistic is 454 base coverage, counts of aligned reads covering a given base, averaged across the accessible genome. For RP detection the driving coverage statistic is Illumina read-pair spanning coverage, counts of fragments in which the non-sequenced segment of the fragment between the reads cover a given base, averaged across the genome (Table S2).
Validation methods
The four non-reference MEI event lists (Table 1) were submitted to the 1000 Genomes Structural Variation subgroup for validation experiments to assess false detection rates. 200 loci from each list were randomly selected for primer design and subsequent PCR validation. Primers were designed as described previously [32], [36] to span across the insertion breakpoint and to guarantee unique mapping to build 36.3. In addition to the estimation of the false detection rates, validation genotypes were derived from gel-band size comparison for each sample and site tested by PCR. We also used the validation data to estimate detection sensitivity based on the overlap of events called between the two independent sequence data platforms and algorithms.
For loci with ambiguous PCR results, no amplification, or amplification of only the empty insertions site, a second primer pair was designed. For the primer design, 600 bp of flanking sequence on either side of the insertion site was retrieved from genome.ucsc.edu using Galaxy. Alu elements within the flanking sequence were masked to “N” using RepeatMasker (repeatmasker.org). Primers were designed with BatchPrimer3 v2.0 in the flanking sequence, leaving at least 100 bp before and after the predicted insertion site. Next, all primers were tested with BLAT to determine the number of matches in the human genome. If one primer of a primer pair matched several times and the other primer was unique, a virtual PCR was performed. Primer combinations with one predicted PCR product were tested on our panel. Otherwise primers were designed manually (if possible) after repeat-masking the flanking sequence with the complete repeat library.
In addition, for L1 and SVA loci without unambiguous PCR amplification, primers were designed, placing one primer within the 3′ end of the mobile element sequence [75]. The primers were designed to match the consensus sequences of the youngest L1 and SVA sub-families. All PCR primers were ordered from Sigma Aldrich, Inc. (St. Louis, MO). All LSU-designed PCR primer sequences used in this project can be found at http://batzerlab.lsu.edu.
DNA samples for PCR verification
A subset of 25 DNA samples from the low coverage pilot samples and all six trio samples were used in PCR validations (Table S4). Each DNA panel also included a population out-group sample, an individual of South American origin (NA17310, Coriell) for low coverage pilot, and an individual of Asian origin (NA17081, Coriell) for the trio pilot. Additional control DNA samples on both panels included human cell line DNA, (HeLa; ATCC CCL-2) as well as “Pop80”, a locally pooled DNA sample from different individuals of diverse geographic origins (Asia, Africa, South American, and European). This sample serves as a diagnostic tool because amplification of an empty site alone in all samples (including Pop80) strongly indicates that the putative insertion is absent (false positive). In contrast, the presence of an MEI in a single study subject, while absent in Pop80, points toward a potential de novo retrotransposon insertion, or at least an insertion with a low allele frequency (AF). Chimpanzee DNA (NS06006, Coriell) was also included on each panel, representing the presumptive pre-insertion site for each event (empty site) as another PCR control.
In addition to the subset of 25 individuals used for the low coverage pilot validations, four more DNA samples from the low coverage pilot dataset were obtained for subsequent experiments. DNA samples NA12872, NA12814, NA12815 and NA12044 (CEPH/Utah USA) were purchased from the Coriell Institute for Medical Research. All 35 samples (25+6+4) were used for PCR validations associated with MEI events detected specifically in exons.
PCR details (LSU)
PCR amplifications were performed in 25 µl reactions in a 96-well format using either a Perkin Elmer GeneAmp 9700 or a BioRad i-cycler thermo-cycler. Each reaction contained 15–50 ng of template DNA; 200 nM of each oligonucleotide primer; 1.5 mM MgCl2, 1× PCR buffer (50 mM KCl; 10 mM TrisHCl, pH 8.3); 0.2 mM dNTPs; and 1–2 U Taq DNA polymerase.
Full-length L1 and SVA elements typically exceed the limitations of standard DNA Taq polymerase in PCR. For L1 insertions, LA-Taq DNA polymerase (Takara Bio USA, Clontech Laboratories, Inc. Mountain View, CA) was used in the PCR reactions according to the manufacturer's instructions to enhance the yield of long PCR templates (2–10 kb). SVA elements are particularly GC-rich and difficult to amplify in PCR if full-length even with special long-template polymerases. In order to evaluate presence/absence of these insertions using PCR, we performed a PCR using one primer residing within the SVA insertion in conjunction with an external primer (forward or reverse, depending on the orientation of the predicted insertion). To determine the genotype and presence of the insertion, two separate PCR reactions were required in these instances. A PCR using primers flanking the MEI amplified a PCR product if the MEI was “absent.” A separate PCR with internal primers detected the MEI “present” site. In addition, this approach was also used for some L1 loci to confirm the presence/absence of the insertion and to minimize the chance of false non-detection.
PCR experiments were carried out in three different laboratories yielding similar success rates. At EMBL, PCRs were preformed using 10 ng of NA12878 genomic DNA (Coriell) in 20 µl volumes in a C1000 thermocycler (BioRad). Two different enzymes, iProof High Fidelity DNA Polymerase (Biorad) and Hotstart Taq (Qiagen) were used, with comparable results. PCR conditions for iProof were: 98°C for 1 min, followed by 5 cycles of 98°C for 10 s, 68°C for 20 s and 72°C for 4 min and 30 cycles of 98°C for 10 s, 66°C for 20 s and 72°C for 4.5 min, followed by a final cycle of 72°C for 5 min. PCR conditions for HotStart Taq were: 94°C for 15 min, followed by 5 cycles of 94°C for 30 s, 60°C for 30 s and 72°C for 3 min and 30 cycles of 94°C for 30 s, 56°C for 30 s and 72°C for 3.5 min, followed by a final cycle of 72°C for 5 min. PCR products were analyzed on a 1% agarose gel stained with Sybr Safe Dye (Invitrogen) and a 100 bp ladder and 1 kb ladder (NEB).
PCR reactions at Louisiana State University were performed under the following conditions: initial denaturation at 94°C for 90 sec, followed by 32 cycles of denaturation at 94°C for 20 sec, annealing at 61°C for primers designed by pipeline or 57°C for other primer design for 20 sec, and extension at 72°C for 30 to 90 sec depending on the predicted PCR amplicon size. PCRs were terminated with a final extension at 72°C for 3 min. When LA-Taq DNA polymerase was used to amplify L1 insertions, the extension step of each cycle was carried out at 68° for 8 min, 30 sec, followed by a final extension step at 68° for 10 minutes at the end of the run. 20 µl of each PCR product were size-fractionated in a horizontal gel chamber on a 2% (Alu and SVA) or 1% (L1) agarose gel containing 0.1 µg/ml ethidium bromide for 60 minutes at 175 V or 1 hour/45 min at 150 V, respectively. UV-fluorescence was used to visualize the DNA fragments and images were saved using a BioRad ChemiDoc XRS imaging system (Hercules, CA).
An outcome from the validation experiments on the 86 gene-interupting MEI was a high false detection rate for candidate Alu insertions in close proximity to 7SLRNA annotations. Subsequently we reclassified all 22 Alu insertion candidates within 200 bp of a 7SLRNA as invalidated (Table S1).
Detection sensitivity
The two non-reference MEI detection methods use independent DNA libraries. So the overlap between the RP and SR are governed by the respective detection sensitivities, statistically akin to the Lincoln-Peterson method [76] used in ecological studies to estimate the size of a population based on two random capture and recapture samplings. This estimate assumes that the two algorithms are sensitive to the same type of events and that the difference between the event lists is a sampling issue. The expression for the detection respective detection sensitivities (εRP and εSR) depends on the false detection rates (fRP and fSR) provided by the validation experiments, the counts of loci detected by each method (nRP and nSR), and the count of loci detected by both methods (nRP.SR):(3)Given detection sensitivities εRP and εSR from independent datasets and methods, the combined detection sensitivity (RP+SR) becomes:(4)for samples in which both types of data were available (e.g. trio samples NA12878 and NA19240).
Genotyping methods
For reference MEI we used available genotypes calculated by GenomeSTRiP [39] for the 1000GP deletion call set. GenomeSTRiP results were not readily available for non-reference MEI so we developed a simple Bayesian framework to estimate the posterior probability for each possible genotype. The posterior genotype probability is:(5)where NALT and NREF are the counts of fragments supporting the alternate and reference alleles respectively; g is the genotype (i.e. homozygous reference allele, heterozygous, homozygous insertion allele); P(g) is the prior probability for the genotype g (a flat prior was used, P(g) = 1/3); pg is the expected fraction of insertion fragments given a genotype g (i.e. pg = 0.5 for heterozygous insertions, pg∼0 for homozygous reference, and pg∼1 for homozygous insertions); Pbin(NALT,NALT+NREF,pg) is the binomial probability that NALT+NREF fragments will fluctuate to NALT, given an expected fraction pg. The called genotype for a given site is the genotype with the maximum posterior probability. The Bayesian framework also provides genotype likelihoods, which are used to construct genotyping quality metric (GQ) for each site and sample. The GQ value adopts the “phred” quality convention:(6)Where P(g|NALT,NREF) is the posterior probability for the called genotype from Eq. (5). GQ is highly dependent on the total number of supporting fragments (reference plus insertion). A selection of sites at GQ = 7 should correspond to roughly to 80% genotyping accuracy and corresponds to sites with 2 or more supporting fragments.
Allele frequency spectra
MEI loci with at least 25 genotyped samples per population (50 samples for the combined population spectra) were included in allele frequency spectra. Sites of GQ≥7 non-reference MEI and of GQ≥10 reference MEI were included. For loci with more than 25 genotyped samples, a random subset of 25 was used for the allele count spectra (Figure 5). For the allele frequency spectra (Figure 6a–6b) we projected down to 25 samples according to the hypergeometric distribution [56], [57] which smooths the spectrum while retaining all available information from loci with more than 25 genotyped samples. Hypergeometric projection was not used to build the allele count spectra used for fitting purposes because it introduces correlation among allele count bins. We constructed the allele count spectra for MEI events detected as insertions and those detected as deletions separately to account for the distinct ascertainment conditions before combining them into the aggregate spectrum. The combined spectrum includes corrections for respective detection and genotyping efficiencies:(7)where nREF(i) and nNREF(i) are the counts of genotyped loci for reference (e.g. Figure 5b) and non-reference MEI (Figure 5a) at allele count i, KREF and KNREF are scaling factors for each detection mode (not dependent on i), and nMEI(i) is the net count of MEI variant loci at a given allele count i (Figure 5c–d). The correction factors depend on the detection sensitivity (εDET) and genotyping efficiency (εGEN) as K = (εDET·εGEN)−1. Genotyping efficiency is simply the fraction of detected sites with 25 more genotyped samples (Table S9). Detection efficiency is described above (Detection specificity and sensitivity, Figure 3d). SNP allele frequency spectra (Figure 6b) were based on the 1000GP release VCF files (ftp://ftp-trace.ncbi.nih.gov/1000genomes/ftp/pilot_data/release/2010_07/) with no corrections. SNP allele frequency spectra were projected down to 50 samples using the hypergeometric distribution [56], [57].
Functional calculation of suppression factor
Only non-reference MEI with insertion position confidence intervals entirely within annotated regions (Gene, UTR, CDS) were counted. No MEI that were subsequently invalidated were counted. Relative to random placement across the genome the MEI suppression or boost factor is defined as:(8)where Ntot is the total number of MEI loci, Ltot = 2.85×109 bp is the length of the accessible genome, Lobs is the size of the region (1 MB or the sum of coding regions) where the number of observed MEI is Nobs. The null model for MEI placement results in a binomially distributed Nobs, which is generally not far from what we observe, except in the case of functional regions (suppressed) and HLA (hotspot). For the calculation of MEI inserted in CDS regions, only non-reference MEI were considered, since an embedded reference MEI precludes annotation as a coding sequence.
Heterozygosity
MEI and SNP heterozygosity for each sample were calculated from the counts of genotyped heterozygous sites. For MEI, the total numbers of genomic heterozygous sites were estimated with corrections for genotyping efficiency and detection sensitivity. The genotyping efficiency for a given sample is the fraction of detected loci with high quality (GQ≥7 non-reference, of GQ≥10 reference MEI) genotypes. There is also a sample specific correction for genotyping bias against heterozygotes at sites with limited fragment coverage:(9)where the sum is over genotyped loci passing the GQ threshold for the given sample, Nloci is the count of such sites, NF is the count of supporting fragments (both reference and insertion allele) at the site and binopdf is the binomial probability density function that a heterozgygous site will randomly produce only reference supporting fragments. The KHET correction was applied only to the non-reference MEI component because, for reference MEI detected as deletions, GenomeSTRiP used not just supporting fragment information for genotype likelihoods, but also used Beagle to impute missing data from linkage with local SNP haplotypes to identify heterozygous deletions. For each sample (s) the number of heterozygous MEI in the genome is estimated as:(10)where πMEI(s) is the heterozygosity for sample s, πREF(s) and πNREF(s) are the raw counts of heterozygous sites for reference and non-reference MEI, εDET is the detection sensitivity, and εGEN(s) is the fraction of detected sites genotyped in the given sample (Figure S13, Table S9). SNP heterozygosity is derived from the raw counts of heterozygous sites. All values of heterozygosity are in units of heterozygous sites per genome, and the length of the genome is considered to be the accessible genome (2.85 Gb) [36].
The SNP heterozygosity values are transformed to rough estimates of the corresponding coalescent time (Figure 7b) [77]:(11)where, μSNP = 1.8×10−8 mutations per site per generation, and TGEN∼25 y is the average time between generations.
Supporting Information
{kind=link}
{kind=link}
Zdroje
1. CordauxRBatzerMA 2009 The impact of retrotransposons on human genome evolution. Nat Rev Genet 10 691 703
2. CordauxRHedgesDJBatzerMA 2004 Retrotransposition of Alu elements: how many sources? Trends Genet 20 464 467
3. DeiningerPLBatzerMAHutchisonCA3rdEdgellMH 1992 Master genes in mammalian repetitive DNA amplification. Trends Genet 8 307 311
4. MillsREBennettEAIskowRCDevineSE 2007 Which transposable elements are active in the human genome? Trends Genet 23 183 191
5. RheadBKarolchikDKuhnRMHinrichsASZweigAS 2010 The UCSC Genome Browser database: update 2010. Nucleic Acids Res 38 D613 619
6. SmitAHubleyRGreenP 2010 RepeatMasker. wwwrepeatmaskerorg
7. KriegsJOChurakovGJurkaJBrosiusJSchmitzJ 2007 Evolutionary history of 7SL RNA-derived SINEs in Supraprimates. Trends Genet 23 158 161
8. BabushokDVKazazianHHJr 2007 Progress in understanding the biology of the human mutagen LINE-1. Hum Mutat 28 527 539
9. BrouhaBSchustakJBadgeRMLutz-PriggeSFarleyAH 2003 Hot L1s account for the bulk of retrotransposition in the human population. Proc Natl Acad Sci U S A 100 5280 5285
10. OstertagEMGoodierJLZhangYKazazianHHJr 2003 SVA elements are nonautonomous retrotransposons that cause disease in humans. Am J Hum Genet 73 1444 1451
11. WangHXingJGroverDHedgesDJHanK 2005 SVA elements: a hominid-specific retroposon family. J Mol Biol 354 994 1007
12. SenSKHanKWangJLeeJWangH 2006 Human genomic deletions mediated by recombination between Alu elements. Am J Hum Genet 79 41 53
13. HanKLeeJMeyerTJRemediosPGoodwinL 2008 L1 recombination-associated deletions generate human genomic variation. Proc Natl Acad Sci U S A 105 19366 19371
14. BelancioVPDeiningerPLRoy-EngelAM 2009 LINE dancing in the human genome: transposable elements and disease. Genome Med 1 97
15. CoufalNGGarcia-PerezJLPengGEYeoGWMuY 2009 L1 retrotransposition in human neural progenitor cells. Nature 460 1127 1131
16. FaulknerGJKimuraYDaubCOWaniSPlessyC 2009 The regulated retrotransposon transcriptome of mammalian cells. Nat Genet 41 563 571
17. DewannieuxMEsnaultCHeidmannT 2003 LINE-mediated retrotransposition of marked Alu sequences. Nature genetics 35 41 48
18. MoranJVHolmesSENaasTPDeBerardinisRJBoekeJD 1996 High frequency retrotransposition in cultured mammalian cells. Cell 87 917 927
19. KazazianHHJrWongCYoussoufianHScottAFPhillipsDG 1988 Haemophilia A resulting from de novo insertion of L1 sequences represents a novel mechanism for mutation in man. Nature 332 164 166
20. MikiYKatagiriTKasumiFYoshimotoTNakamuraY 1996 Mutation analysis in the BRCA2 gene in primary breast cancers. Nat Genet 13 245 247
21. BatzerMADeiningerPL 2002 Alu repeats and human genomic diversity. Nat Rev Genet 3 370 379
22. PangAWMacDonaldJRPintoDWeiJRafiqMA 2010 Towards a comprehensive structural variation map of an individual human genome. Genome Biol 11 R52
23. XingJZhangYHanKSalemAHSenSK 2009 Mobile elements create structural variation: analysis of a complete human genome. Genome Res 19 1516 1526
24. BeckCRCollierPMacfarlaneCMaligMKiddJM 2010 LINE-1 retrotransposition activity in human genomes. Cell 141 1159 1170
25. EwingADKazazianHHJr 2010 High-throughput sequencing reveals extensive variation in human-specific L1 content in individual human genomes. Genome Res
26. HuangCRSchneiderAMLuYNiranjanTShenP 2010 Mobile interspersed repeats are major structural variants in the human genome. Cell 141 1171 1182
27. IskowRCMcCabeMTMillsREToreneSPittardWS 2010 Natural mutagenesis of human genomes by endogenous retrotransposons. Cell 141 1253 1261
28. WitherspoonDJXingJZhangYWatkinsWSBatzerMA 2010 Mobile element scanning (ME-Scan) by targeted high-throughput sequencing. BMC Genomics 11 410
29. WangJSongLGroverDAzrakSBatzerMA 2006 dbRIP: a highly integrated database of retrotransposon insertion polymorphisms in humans. Hum Mutat 27 323 329
30. MillsREWalterKStewartCHandsakerRChenK 2011 Mapping structural variation at fine-scale by population-scale genome sequencing. Nature 470 59 62
31. BentleyDRBalasubramanianSSwerdlowHPSmithGPMiltonJ 2008 Accurate whole human genome sequencing using reversible terminator chemistry. Nature 456 53 59
32. KorbelJOUrbanAEAffourtitJPGodwinBGrubertF 2007 Paired-end mapping reveals extensive structural variation in the human genome. Science 318 420 426
33. SchusterSCMillerWRatanATomshoLPGiardineB 2010 Complete Khoisan and Bantu genomes from southern Africa. Nature 463 943 947
34. EwingADKazazianHH 2010 Whole-genome resequencing allows detection of many rare LINE-1 insertion alleles in humans. Genome Res
35. HormozdiariFAlkanCVenturaMHajirasoulihaIMaligM 2010 Alu repeat discovery and characterization within human genomes. Genome Res
36. Genomes Project Consortium 2010 Towards a comprehensive map of human sequence variation. Nature
37. Chimpanzee Sequencing and Analysis Consortium 2005 Initial sequence of the chimpanzee genome and comparison with the human genome. Nature 437 69 87
38. ChenKWallisJWMcLellanMDLarsonDEKalickiJM 2009 BreakDancer: an algorithm for high-resolution mapping of genomic structural variation. Nat Methods 6 677 681
39. HandsakerREKornJMNemeshJMcCarrollSA 2011 Discovery and genotyping of genome structural polymorphism by sequencing on a population scale. Nat Genet
40. StewartC in preparation SPANNER: a structural variation detection tool
41. YeKSchulzMHLongQApweilerRNingZ 2009 Pindel: a pattern growth approach to detect break points of large deletions and medium sized insertions from paired-end short reads. Bioinformatics 25 2865 2871
42. HormozdiariFAlkanCEichlerEESahinalpSC 2009 Combinatorial algorithms for structural variation detection in high-throughput sequenced genomes. Genome Res 19 1270 1278
43. AbyzovAUrbanAESnyderMGersteinM 2011 CNVnator: An approach to discover, genotype and characterize typical and atypical CNVs from family and population genome sequencing. Genome Res
44. YoonSXuanZMakarovVYeKSebatJ 2009 Sensitive and accurate detection of copy number variants using read depth of coverage. Genome Res 19 1586 1592
45. KiddJMCooperGMDonahueWFHaydenHSSampasN 2008 Mapping and sequencing of structural variation from eight human genomes. Nature 453 56 64
46. LevySSuttonGNgPCFeukLHalpernAL 2007 The diploid genome sequence of an individual human. PLoS Biol 5 e254
47. MillsRELuttigCTLarkinsCEBeauchampATsuiC 2006 An initial map of insertion and deletion (INDEL) variation in the human genome. Genome Res 16 1182 1190
48. GordonDDesmaraisCGreenP 2001 Automated finishing with autofinish. Genome Res 11 614 625
49. KentWJ 2002 BLAT–the BLAST-like alignment tool. Genome Res 12 656 664
50. BrowningSRBrowningBL 2007 Rapid and accurate haplotype phasing and missing-data inference for whole-genome association studies by use of localized haplotype clustering. Am J Hum Genet 81 1084 1097
51. EwingBGreenP 1998 Base-calling of automated sequencer traces using phred. II. Error probabilities. Genome Res 8 186 194
52. KimuraM 1968 Evolutionary rate at the molecular level. Nature 217 624 626
53. WattersonGA 1975 On the number of segregating sites in genetical models without recombination. Theor Popul Biol 7 256 276
54. FuYX 1995 Statistical properties of segregating sites. Theor Popul Biol 48 172 197
55. SchaffnerSFFooCGabrielSReichDDalyMJ 2005 Calibrating a coalescent simulation of human genome sequence variation. Genome Res 15 1576 1583
56. GutenkunstRNHernandezRDWilliamsonSHBustamanteCD 2009 Inferring the joint demographic history of multiple populations from multidimensional SNP frequency data. PLoS Genet 5 e1000695
57. MarthGTCzabarkaEMurvaiJSherryST 2004 The allele frequency spectrum in genome-wide human variation data reveals signals of differential demographic history in three large world populations. Genetics 166 351 372
58. XingJWatkinsWSWitherspoonDJZhangYGutherySL 2009 Fine-scaled human genetic structure revealed by SNP microarrays. Genome Res 19 815 825
59. RedonRIshikawaSFitchKRFeukLPerryGH 2006 Global variation in copy number in the human genome. Nature 444 444 454
60. ThomsonRPritchardJKShenPOefnerPJFeldmanMW 2000 Recent common ancestry of human Y chromosomes: evidence from DNA sequence data. Proc Natl Acad Sci U S A 97 7360 7365
61. NachmanMWCrowellSL 2000 Estimate of the mutation rate per nucleotide in humans. Genetics 156 297 304
62. BurgessRYangZ 2008 Estimation of hominoid ancestral population sizes under bayesian coalescent models incorporating mutation rate variation and sequencing errors. Mol Biol Evol 25 1979 1994
63. ChenFCLiWH 2001 Genomic divergences between humans and other hominoids and the effective population size of the common ancestor of humans and chimpanzees. Am J Hum Genet 68 444 456
64. WallJD 2003 Estimating ancestral population sizes and divergence times. Genetics 163 395 404
65. TajimaF 1989 Statistical method for testing the neutral mutation hypothesis by DNA polymorphism. Genetics 123 585 595
66. MillsREBennettEAIskowRCLuttigCTTsuiC 2006 Recently mobilized transposons in the human and chimpanzee genomes. Am J Hum Genet 78 671 679
67. KondrashovFAKondrashovAS 2010 Measurements of spontaneous rates of mutations in the recent past and the near future. Philos Trans R Soc Lond B Biol Sci 365 1169 1176
68. CordauxRHedgesDJHerkeSWBatzerMA 2006 Estimating the retrotransposition rate of human Alu elements. Gene 373 134 137
69. JurkaJKapitonovVVPavlicekAKlonowskiPKohanyO 2005 Repbase Update, a database of eukaryotic repetitive elements. Cytogenet Genome Res 110 462 467
70. StrombergMPLeeWPMarthGT in preparation MOSAIK: A next-generation reference-guided aligner
71. KnuthDE 1968 The art of computer programming Reading, Mass. Addison-Wesley Pub. Co
72. YouseffS 1987 Clustering with local equivalence relations. Computer Physics Communications 45 423 426
73. HuangW in preparation ART: Next-generation read simulator
74. LiHRuanJDurbinR 2008 Mapping short DNA sequencing reads and calling variants using mapping quality scores. Genome Res 18 1851 1858
75. KonkelMKWangJLiangPBatzerMA 2007 Identification and characterization of novel polymorphic LINE-1 insertions through comparison of two human genome sequence assemblies. Gene 390 28 38
76. SeberGAF 2002 Estimation of animal abundance and related parameters Caldwell, N.J. Blackburn Press xvii, 654 p.
77. HartlDLClarkAG 2007 Principles of population genetics Sunderland, Mass. Sinauer Associates
Štítky
Genetika Reprodukční medicínaČlánek vyšel v časopise
PLOS Genetics
2011 Číslo 8
Nejčtenější v tomto čísle
- An EMT–Driven Alternative Splicing Program Occurs in Human Breast Cancer and Modulates Cellular Phenotype
- Chromosome Painting Reveals Asynaptic Full Alignment of Homologs and HIM-8–Dependent Remodeling of Chromosome Territories during Meiosis
- A Pre-mRNA–Associating Factor Links Endogenous siRNAs to Chromatin Regulation
- Discovery of Sexual Dimorphisms in Metabolic and Genetic Biomarkers