
Risk prediction models for selection of lung cancer screening candidates: A retrospective validation study
Kevin ten Haaf and colleagues present a new prediction model for candidate screening for lung cancer. The new model considers an individual's risk rather than age and pack years smoked.
Published in the journal:
. PLoS Med 14(4): e32767. doi:10.1371/journal.pmed.1002277
Category:
Research Article
doi:
https://doi.org/10.1371/journal.pmed.1002277
Summary
Kevin ten Haaf and colleagues present a new prediction model for candidate screening for lung cancer. The new model considers an individual's risk rather than age and pack years smoked.
Introduction
The National Lung Screening Trial (NLST) found that screening with low-dose computed tomography (CT) can reduce lung cancer mortality by 20% [1]. Based on an evidence review, including the results of the NLST and a comparative microsimulation modeling study, the United States Preventive Services Task Force (USPSTF) recommended lung cancer screening for current and former smokers aged 55 through 80 y who smoked at least 30 pack-years and, if quit, quit less than 15 y ago [2–4]. To our knowledge, only the United States has implemented lung cancer screening policies. Although the province of Ontario, Canada, recommends screening individuals at high risk for lung cancer through an organized program, no program has yet been established [5]. Cancer Care Ontario (the provincial cancer agency of Ontario) is currently evaluating the feasibility of implementing such a program [6]. European countries have not yet made any recommendations on lung cancer screening, as the final results of the Dutch-Belgian Lung Cancer Screening Trial (Nederlands-Leuvens Longkanker Screenings Onderzoek [NELSON] trial), potentially pooled with high-quality data from other trials, are still awaited [7–9].
The screening eligibility criteria used in the current USPSTF recommendations are based on age and pack-years, a measure of cumulative smoking exposure. Thus, these recommendations do not take other important risk factors into account, such as family history, nor other relevant aspects of smoking, such as smoking duration or intensity. Recently, a number of investigations have suggested that determining screening eligibility using an individual’s risk based on age, more detailed smoking history, and other risk factors such as ethnicity and family history of lung cancer could lead to more effective screening programs compared with the USPSTF recommendations [10–13]. Indeed, some lung cancer screening guidelines already encourage assessment of an individual’s risk to determine screening eligibility [14].
While various lung cancer risk prediction models have been developed, external validation and direct comparisons between models have been limited due to insufficient numbers of events or methodological limitations [15–21]. Such validations are essential, as risk prediction models generally have optimistic performance within their development dataset [15–17]. This study aims to externally validate and directly compare the performance of nine currently available lung cancer risk prediction models for stratifying lung cancer risk groups and determining screening eligibility.
Methods
Ethics statement
No identifiable information was used; therefore, no institutional review board (IRB) approval was needed. Nonetheless, a determination of exempt was given by the University of Michigan IRB (HUM00054750), and a determination of this not being human subjects research was given by the Fred Hutchinson Cancer Research Center (former affiliation of J. J.) IRB (6007–680).
Study population
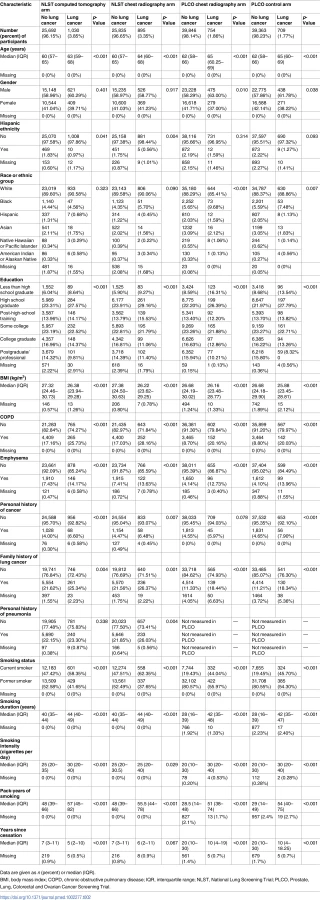
We used data from two large randomized controlled screening trials: the NLST and the Prostate, Lung, Colorectal and Ovarian Cancer Screening Trial (PLCO) [1,22–24]. All participants in the CT arm (n = 26,722) and chest radiography (CXR) arm (n = 26,730) of the NLST and ever-smoking participants in the CXR arm (n = 40,600) and control arm (n = 40,072) of the PLCO were included in the analysis. Never-smokers in the PLCO were not considered, as (1) not all lung cancer risk prediction models can be applied to never-smokers and (2) never-smokers are unlikely to reach levels of risk that allow them to benefit from screening [13,25].
Data on the predictor variables in each trial were collected through epidemiologic questionnaires administered at study entry and harmonized across both trials. Reported average numbers of cigarettes smoked per day above 100 were considered implausible and recoded as 100 cigarettes per day (n = 11). Furthermore, body mass index values less than 14 and over 60 kg/m2 were considered implausible for enrollment in both trials and recoded as 14 (n = 5) and 60 kg/m2 (n = 18), respectively. Lung cancer diagnoses (1,925 in the NLST and 1,463 in the PLCO) and lung cancer deaths (884 in the NLST and 915 in the PLCO) that occurred between study entry and 6 y of follow-up were included in the final dataset and were considered as binary outcomes.
Lung cancer risk prediction models
Our study includes nine risk prediction models for lung cancer incidence or death that have been used frequently in the literature. Risk prediction models were not considered for this investigation, if they (1) were developed for specific ethnicities and are therefore not broadly applicable [26–28], (2) used information on biomarkers or lung nodules and are therefore not readily applicable for the prescreening selection of individuals [29–33], (3) were developed for identifying symptomatic patients [34,35], (4) did not incorporate smoking behavior [36], (5) did not provide information on parameter estimates (e.g., baseline risk parameters) necessary to allow replication of the model [11,12], or (6) had poor discriminative ability in their development dataset [37].
Nine models remained and were investigated: the Bach model, the Liverpool Lung Project (LLP) model, the PLCOm2012 model, the Two-Stage Clonal Expansion (TSCE) model for lung cancer incidence, the Knoke model, two versions of the TSCE model for lung cancer death [10,38–44], and simplified versions of the PLCOm2012 and LLP models. The characteristics of these models are shown in Table 1. The TSCE and Knoke models consider only age, gender, and smoking-related characteristics as risk factors [40–43]. The Bach model considers asbestos exposure as an additional risk factor, while the LLP and PLCOm2012 models consider multiple additional risk factors [10,38,39]. The simplified versions of the PLCOm2012 and LLP models considered only age, gender, and smoking variables. A detailed description of each model can be found in S1 Appendix.

Data on frequency and intensity of asbestos exposure, used in the LLP and Bach models, was not available for the PLCO participants and could not be accurately derived for the NLST participants [38,39]. Therefore, we assumed that none of the participants were exposed to asbestos, even though this assumption may lead to biased estimates [45]. However, as the potential number of individuals with asbestos exposure was low (less than 5% of the NLST participants reported ever working with asbestos), this bias is expected to be minor [46].
The LLP model incorporates age at lung cancer diagnosis of a first-degree relative: early age (60 y or younger) versus late age (older than 60 y) [38]. However, while both the PLCO and the NLST had information about the occurrence of family history of lung cancer (yes/no), neither had information on the age of diagnosis for the affected relative(s). Since the median age of lung cancer diagnosis in the United States is 70 y and the majority of lung cancers occur after the age of 65 y (68.6%), we assumed that lung cancer in first-degree relatives in the PLCO and the NLST always occurred after the age of 60 y [47,48].
In addition, the LLP model incorporates a history of pneumonia as a risk factor [38]. While information on this risk factor was available in the NLST, it was not available in the PLCO. Therefore, we assumed that none of the PLCO participants had a history of pneumonia for the complete case analyses. While 22.1% of NLST participants had a history of pneumonia (Table 2), the association of a history of pneumonia with a lung cancer diagnosis within 6 y was not clear (p = 0.3378 in the CT arm and p = 0.0035 in the CXR arm). Missing history of pneumonia for PLCO participants was imputed by using information from the NLST participants [49].
Statistical analyses
To assess the performance of the risk prediction models, several metrics were employed: calibration, discrimination, and clinical usefulness (net benefit over a range of risk thresholds) [50]. The performance of the investigated risk prediction models was assessed in each trial arm separately, for both lung cancer incidence and lung cancer mortality. We assessed both lung cancer incidence and mortality in both arms of both trials for all investigated risk models, as these outcomes may be influenced differently by screening. Screening may affect the predictive performance for lung cancer incidence, due to the advance in time of detection due to screening (lead time) and the detection of cancers that would never have been detected if screening had not occurred (overdiagnosis) [51–53]. Furthermore, CT screening reduces lung cancer mortality compared to CXR screening, which may influence the predictive performance of models for lung cancer mortality in the CT arm of the NLST [1]. Furthermore, the sensitivity and specificity of each model in the PLCO cohorts were compared to the sensitivity and specificity of the NLST/USPSTF smoking eligibility criteria (being a current or former smoker who smoked at least 30 pack-years and, if quit, quit less than 15 y ago). Model performance was assessed by varying follow-up duration and outcome (5 - and 6-y lung cancer incidence or mortality) to investigate the effect of follow-up duration on the discrimination performance of each model [54]. The 5 - and 6-y time frames were chosen because the LLP and PLCOm2012 models were calibrated to these respective time frames, and complete follow-up of NLST participants was limited to 6 y [10,38]. Since performance was similar for 5 - and 6-y outcomes, only the results of the 6-y outcomes are presented. Performance was evaluated for the risk prediction models as presented in their original publication, without any recalibration or reparameterization to the NLST and the PLCO. The only exception is the PLCOm2012 model, which was originally developed based on data from the control arm of the PLCO [10]. All analyses were performed in R (version 3.3.0) [55].
Aspects of calibration performance
Calibration plots were constructed for the observed proportions of outcome events against the predicted risks for individuals grouped by similar ranges of predicted risk [56]. Perfect predictions should show an ideal 45-degree line that can be described by an intercept of 0 and a slope of 1 in the calibration plot [57]. The calibration intercept quantifies the extent to which a model systematically under - or overestimates a person’s risk; an intercept value of 0 represents perfect calibration in the large. The calibration slope was estimated by logistic regression analysis, using the log odds of the predictions for the single predictor of the binary outcome [50]. For a (near-)perfect calibration in the large, a calibration slope less than 1 reflects that predictions for individuals with low risk are too low and predictions for individuals with high risk are too high [50]. The calibration plots, calibration in the large, and calibration slopes for each model were obtained using the R package rms [58].
Discrimination
Discrimination reflects the capability of a model to distinguish individuals with the event from those without the event; the risk predicted by the model should be higher for individuals with the event compared with those without the event [59]. The area under the receiver operating characteristic curve (AUC) was used to assess discrimination, which ranges between 0.5 and 1.0 for sensible models. The AUCs for each model were obtained using the R package rms [58].
Clinical usefulness
While discrimination and calibration are important statistical properties of a risk prediction model, they do not assess its clinical usefulness [50,54,59]. For example, if a false-negative result causes greater harm than a false-positive result, one would prefer a model with a higher sensitivity over a model that has a greater specificity but a slightly lower sensitivity, even though the latter might have a higher AUC [60].
In the context of selecting individuals for lung cancer screening, a model is clinically useful if applying that model to determine screening eligibility yields a better ratio of benefits to harms than not applying it. Decision curve analysis has been proposed to assess the net benefit of using a risk prediction model [60,61]. Decision curve analysis evaluates the net benefit of a model over a range of risk thresholds, i.e., the level of risk used to classify predictions as positive or negative for the predicted outcome. For example, for the PLCOm2012 model, a risk threshold of 1.51% has been suggested, meaning that individuals with an estimated risk of 1.51% or higher are classified as positive (and thus eligible for screening) and individuals with an estimated risk lower than 1.51% as negative (and thus ineligible for screening) [13].
The net benefit is defined as:


This weighting factor represents how the relative harms of false-positive (classifying a person as eligible for screening who does not develop, or die from, lung cancer) and false-negative (classifying a person as ineligible for screening who develops, or dies from, lung cancer) results are valued at a given risk threshold, i.e., the ratio of harm to benefit, and is estimated by the threshold odds. For example, a risk threshold of 2.5% yields the following weighting factor:

This weighting factor implies that missing one case of lung cancer that could be detected through screening is valued as 39 times worse than unnecessarily screening one person, or that one case should be detected per 40 screened persons. Consequently, the less relative weight one gives to detecting a lung cancer case, the higher the risk threshold one will favor.
The net benefit can then be interpreted as follows: if the net benefit at a risk threshold of 2.5% is 0.002 greater compared with screening all persons eligible according to the NLST criteria, taking the weighing factor into account, this is equivalent to a net improvement in true-positive results of 0.002 × 1,000 = 2 per 1,000 persons assessed for screening eligibility, or a net reduction in false-positive results of 0.002 × 1,000/(0.025/0.975) = 78 per 1,000 persons assessed for screening eligibility [60]. Thus, if the risk model has a positive net benefit at the preferred risk threshold, this indicates that applying the model at this risk threshold provides a better ratio of benefits to harms than current screening guidelines based on pack-years. Decision curves visualize the net benefit over a range of risk thresholds, allowing one to discern whether and at which risk thresholds applying the risk model can be clinically useful [61]. Decision curves were used to determine at which range of risk thresholds applying the models provides a net benefit over using the NLST eligibility criteria for selecting individuals for lung cancer screening.
Finally, we identified the risk threshold for each model in the PLCO cohorts that selected a similar number of individuals for screening as the NLST eligibility criteria, on which most lung cancer screening recommendations are currently based. We then assessed the sensitivity (the number of individuals with lung cancer incidence or death classified as eligible for screening divided by the total number of individuals with lung cancer incidence or death) and specificity (the number of individuals without lung cancer incidence or death classified as ineligible for screening divided by the total number of individuals without lung cancer incidence or death) for each model compared to the NLST criteria at the chosen risk threshold, as reported before by Tammemägi et al. [13].
Multiple imputation of missing values
Multiple imputation of missing data for all considered risk factors was performed through the method of chained equations using the R package MICE [62]. History of pneumonia was not measured in the PLCO but was measured in the NLST; therefore, data from the NLST were used to impute history of pneumonia for PLCO participants [49]. Analyses were performed using 20 imputations, and the results were pooled through applying Rubin’s rules [63]. The results of the analyses with imputation of missing variables were similar to those obtained from complete case analyses. The Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD) guidelines suggest applying multiple imputation when missing data are present, as complete case analyses can lead to inefficient estimates [64,65]. Therefore, all analyses reported here were performed with multiple imputation of missing values.
Results
Characteristics of study populations
An overview of the characteristics of the four study cohorts (two trial arms in each trial) is given in Table 2, stratified by 6-y lung cancer incidence. A similar table stratifying participants by 6-y lung cancer mortality is provided in S2 Appendix. An overview of the proportion of individuals with complete information on all risk factors, stratified by trial arm and 6-y outcome, is given in S3 Appendix. Overall, approximately 93% of the study population had complete information for all considered risk factors.
Differences in levels of absolute risk
The risk prediction models included in this study were developed in different populations (Table 1) and incorporate risk factors, specifically smoking behavior, in different ways (S1 Appendix). In addition, some models predict lung cancer incidence, while others predict lung cancer mortality. Therefore, the estimated absolute risk for the same individual varies between models [66]. Fig 1 shows the estimated 6-y risk of lung cancer incidence or mortality (depending on the target outcome of the model) across the models for five individuals with different risk factor profiles. This difference in estimated absolute risk between models suggests that specific risk thresholds might be needed for each model.

Aspects of calibration performance
Overall, all models showed satisfactory calibration performance (S4 Appendix). The models showed the best calibration performance when they were applied to their target outcome, i.e., lung cancer incidence rather than lung cancer mortality for lung cancer incidence models. The calibration was better for all models in the PLCO datasets than in the NLST datasets.
Discrimination
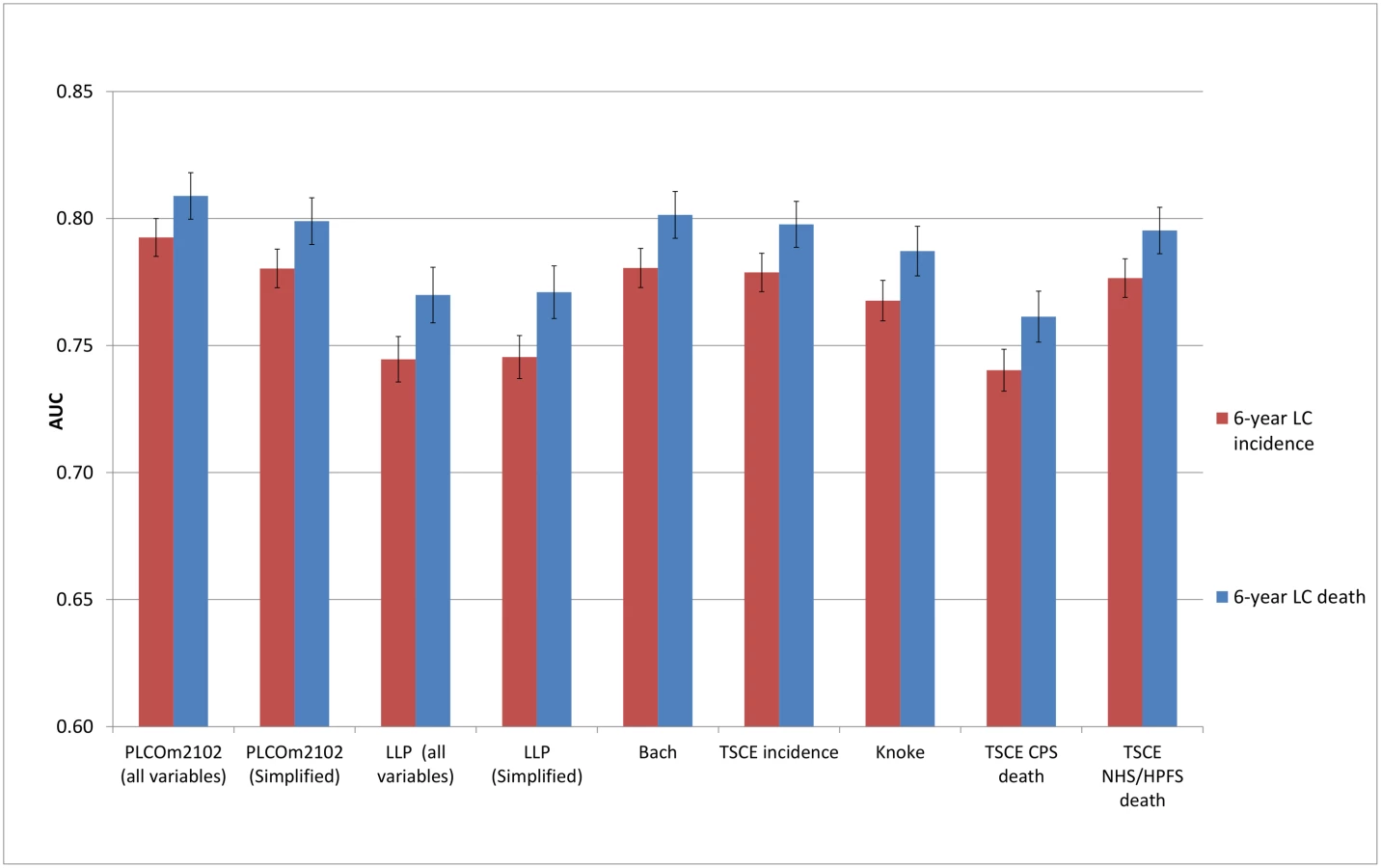
The discriminative performance of the models (Figs 2–5) was better in the PLCO datasets (AUCs ranging from 0.74 to 0.81) than in the NLST datasets (AUCs ranging from 0.61 to 0.73). The discriminative performance of most models was better for lung cancer mortality than for lung cancer incidence (i.e., the AUCs of most models were higher for lung cancer mortality than for lung cancer incidence) in all datasets, except for the PLCO control arm. The PLCOm2012 model (and its simplified version), the Bach model, and the TSCE incidence model showed the best discriminative performance across all datasets regardless of the type of predicted outcome. The discriminative performance of the models was similar for 5 - and 6-y time frames, as shown in S5 Appendix.



Clinical usefulness
Decision curve analysis for each risk prediction model provided a range of risk thresholds that yield a positive net benefit compared with the NLST eligibility criteria. Table 3 shows the lower and upper bounds for these ranges of risk thresholds for 6-y lung cancer incidence across all datasets. Overall, the lower and upper thresholds varied by model, but the ranges were roughly consistent across models, going from approximately 0.1% to 16.7%. This suggests that applying the models is useful for determining screening eligibility if missing one case of lung cancer that could be detected through screening is perceived as being between 999 and 5 times worse than unnecessarily screening one person. More detailed results for the decision curve analyses for both lung cancer incidence and mortality are shown in S6 Appendix.

Comparison to National Lung Screening Trial eligibility criteria
Applying the NLST eligibility criteria yielded a sensitivity of 71.4% (95% confidence interval: 68.0%–74.6%) and a specificity of 62.2% (95% confidence interval: 61.7%–62.7%) for 6-y lung cancer incidence in the PLCO CXR arm (Fig 6; Table 4). The sensitivity and specificity of each of the risk prediction models were higher than those of the NLST eligibility criteria. The PLCOm2012 model, in particular, followed by the Bach model and the TSCE incidence model had the highest sensitivities (all three models >79.8%) and specificities (all three models >62.3%) among all evaluated models. Fig 6 also shows the risk thresholds for each model that select a similar number of individuals for screening as the NLST eligibility criteria. Similar results were found for the PLCO control arm and for using 6-y lung cancer death as the outcome measure (S7 Appendix).


Discussion
This study assessed the performance of nine lung cancer risk prediction models in two large randomized controlled trials: the NLST and the PLCO. The models had satisfactory calibration, had modest to good discrimination, and provided a substantial range of risk thresholds with a positive net benefit compared with the NLST eligibility criteria. Given appropriate model-specific risk thresholds, all risk prediction models had a better sensitivity and specificity than the NLST eligibility criteria. This implies that lung cancer risk prediction models, when coupled with model-specific risk thresholds, outperform currently recommended lung cancer screening eligibility criteria (Tables 3 and 4; Fig 6).
The risk prediction models considered in this study were developed in various cohorts for different outcome measures (lung cancer incidence versus mortality), with fundamental differences in model structures. Consequently, the absolute risk estimates differed between models, which led to differences in calibration performance between the models, specifically in the NLST cohorts. In addition, there were clear differences in discriminative ability between the models. The discriminative ability of all models was better in the PLCO cohorts than in the NLST cohorts, which may be caused by the higher heterogeneity in risk factor profiles among individuals in the PLCO compared with the NLST [67,68]. The NLST required individuals to have smoked at least 30 pack-years and included only current and former smokers (who quit less than 15 y ago), whereas the PLCO did not have any criteria for enrollment with regards to smoking history. In line with these criteria, the average NLST participant had a higher lung cancer risk than the average PLCO participant. The results of our investigation suggest that the discriminative ability of the evaluated models may be lower in groups at elevated risk, which may be due to the lower heterogeneity in risk among participants in these groups [67,68]. However, randomized clinical trials suggest that the results of CT screening may provide an opportunity to improve risk stratification in these groups. In the NLST, participants with a negative prevalence screen had a substantially lower risk of developing lung cancer than participants with a positive prevalence screen [69]. Similarly, in the NELSON trial, the 2-y probability of developing lung cancer after a CT screen varied substantially by pulmonary nodule size and the volume doubling time of these pulmonary nodules [8]. Therefore, incorporating the results of CT screening could improve the risk stratification in groups of individuals at elevated risk. Finally, while there was little difference in specificity between the models at risk thresholds similar to the NLST eligibility criteria, there was a clear difference in sensitivity. In particular, the PLCOm2012 model, followed by the Bach model and the TSCE incidence model, had the best performance across all aspects investigated in this study.
Previous studies have also compared the performance of different lung cancer risk prediction models [20,21]. D’Amelio et al. examined the discriminatory performance of three risk prediction models for lung cancer incidence in a case–control study and found modest differences between the models [20]. However, this study considered a limited number of participants (1,066 cases and 677 controls) and did not consider other aspects of model performance such as calibration or clinical usefulness. Li et al. examined four risk prediction models for lung cancer incidence in German participants of the European Prospective Investigation into Cancer and Nutrition cohort [21]. They found that while the differences between most of the evaluated models were modest, generally only the Bach and the PLCOm2012 models had similar or better sensitivity and specificity compared to the eligibility criteria used in the NLST and other eligibility criteria that were used in various European lung cancer screening trials (which applied less restrictive smoking eligibility criteria than the NLST). This cohort consisted of 20,700 individuals, but fewer than 100 lung cancer cases occurred, which limits statistical power for external validation [18,19].
In contrast to these previous studies, we performed a comprehensive validation, including aspects of calibration, discriminative ability, and clinical usefulness, for many models, in a large sample (n = 134,124) with 3,388 lung cancer cases and 1,799 lung cancer deaths. In addition, while our study supports earlier findings that risk prediction models outperform the NLST eligibility criteria, it also suggests that the PLCOm2012 model followed by the Bach and TSCE incidence models perform better than other models in all investigated aspects.
Our study has some limitations. While our results provide indications regarding at which risk thresholds the investigated risk models can be clinically useful, the optimal thresholds to apply remain uncertain. Determining optimal thresholds requires information on the long-term benefits (such as life-years gained and mortality reduction) and harms (such as overdiagnosis) of applying these thresholds [60]. Natural history modeling may provide further information on the trade-off between the long-term benefits and harms for screening programs with different risk thresholds, similarly to how our previous study informed the USPSTF on its recommendations for lung cancer screening [2].
Another limitation is that information on some of the predictor variables included in the evaluated risk prediction models was not available in the NLST and the PLCO, e.g., asbestos exposure was missing in both cohorts. However, only a few variables were unavailable. Furthermore, some of the evaluated models that used only age, gender, and smoking behavior, such as the TSCE models and the Knoke model, performed similarly to the other models that used additional information on risk factors, suggesting that age, gender, and smoking behavior are the most important risk factors for lung cancer. Thus, the improved performance of these models over the NLST eligibility criteria may primarily be due to the inclusion of detailed smoking behavior in these models. The NLST eligibility criteria use a dichotomized criterion for accumulated pack-years, e.g., an exposure of at least 30 pack-years, which leads to a loss of information for continuous variables [70]. Furthermore, pack-years are estimated by smoking duration and intensity (cigarettes per day), and previous studies indicate that both components contribute independently to an individual’s risk for developing lung cancer; an aggregation of both may not fully capture the effects of smoking on lung cancer risk [10,43,71].
We chose to evaluate the models for varying follow-up lengths (5 - and 6-y time frames) to investigate the effect of follow-up duration on the discrimination performance of each model [54]. Although the discriminative performance of the models was similar for 5 - and 6-y time frames (S5 Appendix), this may not be the case for more disparate time frames.
A number of pertinent questions remain with regards to the implementation of lung cancer screening [9]. Current guidelines like the USPSTF recommendations suggest that individuals should be asked, at a minimum, about their age and smoking history [3]. A number of the models evaluated in our study use information on additional risk factors, such as personal history of cancer, which could be a potential barrier for implementing lung cancer screening based on risk prediction models. However, the LLP and PLCOm2012 models were successfully used to recruit individuals for the UK Lung Cancer Screening Trial (UKLS) and the Pan-Canadian Early Detection of Lung Cancer Study (PanCan), respectively, through short questionnaires [33,72]. This suggests that acquiring information on the risk factors required for these models does not pose a major barrier for implementation. Furthermore, for some risk models, such as the Bach and PLCOm2012 models, online calculators are available, which provide opportunities for fast risk estimation in clinical practice [73–76]. For example, the PLCOm2012 model has been embedded in a lung cancer screening decision aid that has been widely adopted and that can be used to satisfy the Centers for Medicare & Medicaid Services reimbursement requirement for shared decision making [75–77].
In conclusion, our study suggests that lung cancer screening selection criteria can be improved through the explicit application of risk prediction models rather than using criteria based on age and pack-years as a summary measure of smoking exposure. These models might also be helpful for improving the shared decision-making process for lung cancer screening recommended by the USPSTF and required in the US by the Centers for Medicare & Medicaid Services [3,75,78]. However, recommendations for the implementation of risk-based lung cancer screening require a thorough evaluation of the benefits and harms of risk-based screening, as well as an assessment of the feasibility of implementing strategies based on risk models. Therefore, future studies need to evaluate the long-term benefits and harms of applying risk prediction models at different risk thresholds, while considering the potential challenges for implementation, and compare these with the expected benefits and harms of current guidelines.
Supporting Information
Zdroje
1. Aberle DR, Adams AM, Berg CD, Black WC, Clapp JD, Fagerstrom RM, et al. Reduced lung-cancer mortality with low-dose computed tomographic screening. N Engl J Med. 2011;365(5):395–409. doi: 10.1056/NEJMoa1102873 21714641
2. de Koning HJ, Meza R, Plevritis SK, ten Haaf K, Munshi VN, Jeon J, et al. Benefits and harms of computed tomography lung cancer screening strategies: a comparative modeling study for the U.S. Preventive Services Task Force. Ann Intern Med. 2014;160(5):311–20. doi: 10.7326/M13-2316 24379002
3. Moyer VA. Screening for lung cancer: U.S. Preventive Services Task Force recommendation statement. Ann Intern Med. 2014;160(5):330–8. doi: 10.7326/M13-2771 24378917
4. Humphrey LL, Deffebach M, Pappas M, Baumann C, Artis K, Mitchell JP, et al. Screening for lung cancer with low-dose computed tomography: a systematic review to update the US Preventive services task force recommendation. Ann Intern Med. 2013;159(6):411–20. doi: 10.7326/0003-4819-159-6-201309170-00690 23897166
5. Roberts H, Walker-Dilks C, Sivjee K, Ung Y, Yasufuku K, Hey A, et al. Screening high-risk populations for lung cancer: guideline recommendations. J Thorac Oncol. 2013;8(10):1232–7. doi: 10.1097/JTO.0b013e31829fd3d5 24457233
6. Tammemägi M, Hader J, Yu M, Govind K, Svara E, Yurcan M, et al. P1.03–059: organized high risk lung cancer screening in Ontario, Canada: a multi-centre prospective evaluation. J Thorac Oncol. 2017;12(1):S579.
7. Field JK, Hansell DM, Duffy SW, Baldwin DR. CT screening for lung cancer: countdown to implementation. Lancet Oncol. 2013;14(13):e591–600. doi: 10.1016/S1470-2045(13)70293-6 24275132
8. Horeweg N, van Rosmalen J, Heuvelmans MA, van der Aalst CM, Vliegenthart R, Scholten ET, et al. Lung cancer probability in patients with CT-detected pulmonary nodules: a prespecified analysis of data from the NELSON trial of low-dose CT screening. Lancet Oncol. 2014;15(12):1332–41. doi: 10.1016/S1470-2045(14)70389-4 25282285
9. van der Aalst CM, ten Haaf K, de Koning HJ. Lung cancer screening: latest developments and unanswered questions. Lancet Respir Med. 2016;4(9):749–61. doi: 10.1016/S2213-2600(16)30200-4 27599248
10. Tammemägi MC, Katki HA, Hocking WG, Church TR, Caporaso N, Kvale PA, et al. Selection criteria for lung-cancer screening. N Engl J Med. 2013;368(8):728–36. doi: 10.1056/NEJMoa1211776 23425165
11. Kovalchik SA, Tammemagi M, Berg CD, Caporaso NE, Riley TL, Korch M, et al. Targeting of low-dose CT screening according to the risk of lung-cancer death. N Engl J Med. 2013;369(3):245–54. doi: 10.1056/NEJMoa1301851 23863051
12. Katki HA, Kovalchik SA, Berg CD, Cheung LC, Chaturvedi AK. Development and validation of risk models to select ever-smokers for CT lung cancer screening. JAMA. 2016;315(21):2300–11. doi: 10.1001/jama.2016.6255 27179989
13. Tammemagi MC, Church TR, Hocking WG, Silvestri GA, Kvale PA, Riley TL, et al. Evaluation of the lung cancer risks at which to screen ever - and never-smokers: screening rules applied to the PLCO and NLST cohorts. PLoS Med. 2014;11(12):e1001764. doi: 10.1371/journal.pmed.1001764 25460915
14. Jaklitsch MT, Jacobson FL, Austin JHM, Field JK, Jett JR, Keshavjee S, et al. The American Association for Thoracic Surgery guidelines for lung cancer screening using low-dose computed tomography scans for lung cancer survivors and other high-risk groups. J Thorac Cardiovasc Surg. 2012;144(1):33–8. doi: 10.1016/j.jtcvs.2012.05.060 22710039
15. Collins GS, Moons KGM. Comparing risk prediction models. BMJ. 2012;344:e3186. doi: 10.1136/bmj.e3186 22628131
16. Altman DG, Vergouwe Y, Royston P, Moons KGM. Prognosis and prognostic research: validating a prognostic model. BMJ. 2009;338:b605. doi: 10.1136/bmj.b605 19477892
17. Siontis GCM, Tzoulaki I, Siontis KC, Ioannidis JPA. Comparisons of established risk prediction models for cardiovascular disease: systematic review. BMJ. 2012;344:e3318. doi: 10.1136/bmj.e3318 22628003
18. Vergouwe Y, Steyerberg EW, Eijkemans MJC, Habbema JDF. Substantial effective sample sizes were required for external validation studies of predictive logistic regression models. J Clin Epidemiol. 2005;58(5):475–83. doi: 10.1016/j.jclinepi.2004.06.017 15845334
19. Collins GS, Ogundimu EO, Altman DG. Sample size considerations for the external validation of a multivariable prognostic model: a resampling study. Stat Med. 2016;35(2):214–26. doi: 10.1002/sim.6787 26553135
20. D’Amelio AM Jr, Cassidy A, Asomaning K, Raji OY, Duffy SW, Field JK, et al. Comparison of discriminatory power and accuracy of three lung cancer risk models. Br J Cancer. 2010;103(3):423–9. doi: 10.1038/sj.bjc.6605759 20588271
21. Li K, Hüsing A, Sookthai D, Bergmann M, Boeing H, Becker N, et al. Selecting high-risk individuals for lung cancer screening: a prospective evaluation of existing risk models and eligibility criteria in the German EPIC cohort. Cancer Prev Res (Phila). 2015;8(9):777–85.
22. National Lung Screening Trial Research Team, Aberle DR, Berg CD, Black WC, Church TR, Fagerstrom RM, et al. The National Lung Screening Trial: overview and study design. Radiology. 2011;258(1):243–53. doi: 10.1148/radiol.10091808 21045183
23. Oken MM, Hocking WG, Kvale PA, Andriole GL, Buys SS, Church TR, et al. Screening by chest radiograph and lung cancer mortality: the Prostate, Lung, Colorectal, and Ovarian (PLCO) randomized trial. JAMA. 2011;306(17):1865–73. doi: 10.1001/jama.2011.1591 22031728
24. Prorok PC, Andriole GL, Bresalier RS, Buys SS, Chia D, Crawford ED, et al. Design of the Prostate, Lung, Colorectal and Ovarian (PLCO) Cancer Screening Trial. Control Clin Trials. 2000;21(6, Suppl 1):273S–309S.
25. ten Haaf K, de Koning HJ. Should never-smokers at increased risk for lung cancer be screened? J Thorac Oncol. 2015;10(9):1285–91. doi: 10.1097/JTO.0000000000000593 26287320
26. Etzel CJ, Kachroo S, Liu M, D’Amelio A, Dong Q, Cote ML, et al. Development and validation of a lung cancer risk prediction model for African-Americans. Cancer Prev Res (Phila). 2008;1(4):255–65.
27. Li H, Yang L, Zhao X, Wang J, Qian J, Chen H, et al. Prediction of lung cancer risk in a Chinese population using a multifactorial genetic model. BMC Med Genet. 2012;13(1):118.
28. Park S, Nam B-H, Yang H-R, Lee JA, Lim H, Han JT, et al. Individualized risk prediction model for lung cancer in Korean men. PLoS ONE. 2013;8(2):e54823. doi: 10.1371/journal.pone.0054823 23408946
29. El-Zein RA, Lopez MS, D’Amelio AM Jr, Liu M, Munden RF, Christiani D, et al. The cytokinesis blocked micronucleus assay as a strong predictor of lung cancer: extension of a lung cancer risk prediction model. Cancer Epidemiol Biomarkers Prev. 2014;23(11):2462–70. doi: 10.1158/1055-9965.EPI-14-0462 25172871
30. Maisonneuve P, Bagnardi V, Bellomi M, Spaggiari L, Pelosi G, Rampinelli C, et al. Lung cancer risk prediction to select smokers for screening CT—a model based on the Italian COSMOS trial. Cancer Prev Res (Phila). 2011;4(11):1778–89.
31. Spitz MR, Etzel CJ, Dong Q, Amos CI, Wei Q, Wu X, et al. an expanded risk prediction model for lung cancer. Cancer Prev Res (Phila). 2008;1(4):250–4.
32. Hoggart C, Brennan P, Tjonneland A, Vogel U, Overvad K, Østergaard JN, et al. A risk model for lung cancer incidence. Cancer Prev Res (Phila). 2012;5(6):834–46.
33. McWilliams A, Tammemagi MC, Mayo JR, Roberts H, Liu G, Soghrati K, et al. Probability of cancer in pulmonary nodules detected on first screening CT. N Engl J Med. 2013;369(10):910–9. doi: 10.1056/NEJMoa1214726 24004118
34. Hippisley-Cox J, Coupland C. Identifying patients with suspected lung cancer in primary care: derivation and validation of an algorithm. Br J Gen Pract. 2011;61(592):e715–23. doi: 10.3399/bjgp11X606627 22054335
35. Iyen-Omofoman B, Tata LJ, Baldwin DR, Smith CJP, Hubbard RB. Using socio-demographic and early clinical features in general practice to identify people with lung cancer earlier. Thorax. 2013;68(5):451–9. doi: 10.1136/thoraxjnl-2012-202348 23321602
36. Young RP, Hopkins RJ, Hay BA, Epton MJ, Mills GD, Black PN, et al. A gene-based risk score for lung cancer susceptibility in smokers and ex-smokers. Postgrad Med J. 2009;85(1008):515–24. doi: 10.1136/pgmj.2008.077107 19789190
37. Spitz MR, Hong WK, Amos CI, Wu X, Schabath MB, Dong Q, et al. A risk model for prediction of lung cancer. J Natl Cancer Inst. 2007;99(9):715–26. doi: 10.1093/jnci/djk153 17470739
38. Raji OY, Duffy SW, Agbaje OF, Baker SG, Christiani DC, Cassidy A, et al. Predictive accuracy of the Liverpool Lung Project risk model for stratifying patients for computed tomography screening for lung cancer: a case–control and cohort validation study. Ann Intern Med. 2012;157(4):242–50. doi: 10.7326/0003-4819-157-4-201208210-00004 22910935
39. Bach PB, Kattan MW, Thornquist MD, Kris MG, Tate RC, Barnett MJ, et al. Variations in lung cancer risk among smokers. J Natl Cancer Inst. 2003;95(6):470–8. 12644540
40. Knoke JD, Burns DM, Thun MJ. The change in excess risk of lung cancer attributable to smoking following smoking cessation: an examination of different analytic approaches using CPS-I data. Cancer Causes Control. 2007;19(2):207–19. doi: 10.1007/s10552-007-9086-5 17992575
41. Hazelton WD, Clements MS, Moolgavkar SH. Multistage carcinogenesis and lung cancer mortality in three cohorts. Cancer Epidemiol Biomarkers Prev. 2005;14(5):1171–81. doi: 10.1158/1055-9965.EPI-04-0756 15894668
42. Hazelton WD, Jeon J, Meza R, Moolgavkar SH. Chapter 8: the FHCRC lung cancer model. Risk Anal. 2012;32:S99–116. doi: 10.1111/j.1539-6924.2011.01681.x 22882896
43. Meza R, Hazelton W, Colditz G, Moolgavkar S. Analysis of lung cancer incidence in the Nurses’ Health and the Health Professionals’ Follow-Up Studies using a multistage carcinogenesis model. Cancer Causes Control. 2008;19(3):317–28. doi: 10.1007/s10552-007-9094-5 18058248
44. Cassidy A, Myles JP, van Tongeren M, Page RD, Liloglou T, Duffy SW, et al. The LLP risk model: an individual risk prediction model for lung cancer. Br J Cancer. 2008;98(2):270–6. doi: 10.1038/sj.bjc.6604158 18087271
45. Gorelick MH. Bias arising from missing data in predictive models. J Clin Epidemiol. 2006;59(10):1115–23. doi: 10.1016/j.jclinepi.2004.11.029 16980153
46. National Lung Screening Trial Research Team, Aberle DR, Adams AM, Berg CD, Clapp JD, Clingan KL, et al. Baseline characteristics of participants in the randomized National Lung Screening Trial. J Natl Cancer Inst. 2010;102(23):1771–9. doi: 10.1093/jnci/djq434 21119104
47. Howlader N, Noone AM, Krapcho M, Garshell J, Miller D, Altekruse SF, et al., editors. SEER Cancer Statistics Review, 1975–2012. Bethesda (Maryland): National Cancer Institute; 2015 Apr [cited 2017 Mar 1]. http://seer.cancer.gov/csr/1975_2012/.
48. National Cancer Institute. Cancer stat facts: lung and bronchus cancer. Bethesda (Maryland): National Cancer Institute; 2016 [cited 2016 Mar 4]. http://seer.cancer.gov/statfacts/html/lungb.html.
49. Jolani S, Debray T, Koffijberg H, Buuren S, Moons KGM. Imputation of systematically missing predictors in an individual participant data meta-analysis: a generalized approach using MICE. Stat Med. 2015;34(11):1841–63. doi: 10.1002/sim.6451 25663182
50. Steyerberg EW, Vergouwe Y. Towards better clinical prediction models: seven steps for development and an ABCD for validation. Eur Heart J. 2014;35(29):1925–31. doi: 10.1093/eurheartj/ehu207 24898551
51. Etzioni R, Gulati R, Mallinger L, Mandelblatt J. Influence of study features and methods on overdiagnosis estimates in breast and prostate cancer screening. Ann Intern Med. 2013;158(11):831–8. doi: 10.7326/0003-4819-158-11-201306040-00008 23732716
52. Patz EF Jr, Pinsky P, Gatsonis C, Sicks JD, Kramer BS, Tammenägi MC, et al. Overdiagnosis in low-dose computed tomography screening for lung cancer. JAMA Intern Med. 2014;174(2):269–74. doi: 10.1001/jamainternmed.2013.12738 24322569
53. ten Haaf K, de Koning HJ. Overdiagnosis in lung cancer screening: why modelling is essential. J Epidemiol Community Health. 2015;69(11):1035–9. doi: 10.1136/jech-2014-204079 26071497
54. Vickers AJ, Cronin AM. Everything you always wanted to know about evaluating prediction models (but were too afraid to ask). Urology. 2010;76(6):1298–301. doi: 10.1016/j.urology.2010.06.019 21030068
55. R Core Team. R: a language and environment for statistical computing. Version 3.3.0. Vienna: R Foundation for Statistical Computing; 2016.
56. Royston P, Moons KGM, Altman DG, Vergouwe Y. Prognosis and prognostic research: developing a prognostic model. BMJ. 2009;338:b604. doi: 10.1136/bmj.b604 19336487
57. Van Calster B, Nieboer D, Vergouwe Y, De Cock B, Pencina MJ, Steyerberg EW. A calibration hierarchy for risk models was defined: from utopia to empirical data. J Clin Epidemiol. 2016;74 : 167–76. doi: 10.1016/j.jclinepi.2015.12.005 26772608
58. Harrell FE Jr. rms: regression modeling strategies. Version 4.3–1. Comprehensive R Archive Network; 2014 [cited 2017 Mar 1]. http://CRAN.R-project.org/package=rms.
59. Steyerberg EW. Clinical prediction models: a practical approach to development, validation, and updating. New York: Springer; 2009.
60. Vickers AJ, Elkin EB. Decision curve analysis: a novel method for evaluating prediction models. Med Decis Making. 2006;26(6):565–74. doi: 10.1177/0272989X06295361 17099194
61. Vickers AJ, Cronin AM, Elkin EB, Gonen M. Extensions to decision curve analysis, a novel method for evaluating diagnostic tests, prediction models and molecular markers. BMC Med Inform Decis Mak. 2008;8 : 53. doi: 10.1186/1472-6947-8-53 19036144
62. van Buuren S, Groothuis-Oudshoorn K. mice: multivariate imputation by chained equations in R. J Stat Softw. 2011;45(3):67.
63. Rubin DB. Multiple imputation for nonresponse in surveys. New York: Wiley; 1987.
64. Moons KGM, Altman DG, Reitsma JB, Ioannidis JPA, Macaskill P, Steyerberg EW, et al. Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD): explanation and elaboration. Ann Intern Med. 2015;162(1):W1–73. doi: 10.7326/M14-0698 25560730
65. van der Heijden GJMG, Donders ART, Stijnen T, Moons KGM. Imputation of missing values is superior to complete case analysis and the missing-indicator method in multivariable diagnostic research: a clinical example. J Clin Epidemiol. 2006;59(10):1102–9. doi: 10.1016/j.jclinepi.2006.01.015 16980151
66. Steyerberg EW, Eijkemans MJC, Boersma E, Habbema JDF. Equally valid models gave divergent predictions for mortality in acute myocardial infarction patients in a comparison of logical regression models. J Clin Epidemiol. 2005;58(4):383–90. doi: 10.1016/j.jclinepi.2004.07.008 15862724
67. Vergouwe Y, Moons KGM, Steyerberg EW. External validity of risk models: use of benchmark values to disentangle a case-mix effect from incorrect coefficients. Am J Epidemiol. 2010;172(8):971–80. doi: 10.1093/aje/kwq223 20807737
68. Debray TPA, Vergouwe Y, Koffijberg H, Nieboer D, Steyerberg EW, Moons KGM. A new framework to enhance the interpretation of external validation studies of clinical prediction models. J Clin Epidemiol. 2015;68(3):279–89. doi: 10.1016/j.jclinepi.2014.06.018 25179855
69. Patz EF Jr, Greco E, Gatsonis C, Pinsky P, Kramer BS, Aberle DR. Lung cancer incidence and mortality in National Lung Screening Trial participants who underwent low-dose CT prevalence screening: a retrospective cohort analysis of a randomised, multicentre, diagnostic screening trial. Lancet Oncol. 2016;17(5):590–9. doi: 10.1016/S1470-2045(15)00621-X 27009070
70. Royston P, Altman DG, Sauerbrei W. Dichotomizing continuous predictors in multiple regression: a bad idea. Stat Med. 2006;25(1):127–41. doi: 10.1002/sim.2331 16217841
71. Thun MJ, Carter BD, Feskanich D, Freedman ND, Prentice R, Lopez AD, et al. 50-year trends in smoking-related mortality in the United States. N Engl J Med. 2013;368(4):351–64. doi: 10.1056/NEJMsa1211127 23343064
72. McRonald FE, Yadegarfar G, Baldwin DR, Devaraj A, Brain KE, Eisen T, et al. The UK Lung Screen (UKLS): demographic profile of first 88,897 approaches provides recommendations for population screening. Cancer Prev Res (Phila). 2014;7(3):362.
73. Brock University. Lung cancer risk calculators. St. Catharines (Ontario): Brock University; 2016 [cited 2016 Dec 19]. https://brocku.ca/lung-cancer-risk-calculator.
74. Memorial Sloan Kettering Cancer Center. Lung cancer screening decision tool. New York:Memorial Sloan Kettering Cancer Center; 2016 [cited 2016 Dec 19]. https://www.mskcc.org/cancer-care/types/lung/screening/lung-screening-decision-tool.
75. Lau YK, Caverly TJ, Cao P, Cherng ST, West M, Gaber C, et al. Evaluation of a personalized, web-based decision aid for lung cancer screening. Am J Prev Med. 2015;49(6):e125–9. doi: 10.1016/j.amepre.2015.07.027 26456873
76. University of Michigan. Lung cancer CT screening [decision aid]. Ann Arbor: University of Michigan; 2016 [cited 2016 Dec 21]. http://www.shouldiscreen.com/.
77. American College of Radiology. Lung cancer screening resources. Reston (Virginia): American College of Radiology; 2016 [cited 2016 Dec 21]. https://www.acr.org/Quality-Safety/Resources/Lung-Imaging-Resources.
78. Jensen TS, Chin J, Ashby L, Hermansen J, Hutter JD. Decision memo for screening for lung cancer with low dose computed tomography (LDCT) (CAG-00439N). Baltimore: Centers for Medicare & Medicaid Services; 2015 [cited 2016 Aug 15]. https://www.cms.gov/medicare-coverage-database/details/nca-decision-memo.aspx?NCAId=274.
Štítky
Interní lékařstvíČlánek vyšel v časopise
PLOS Medicine
2017 Číslo 4
- Alternativní léčebné možnosti u hypercholesterolemie při intoleranci statinů
- Vliv kombinace nutraceutik na remodelaci levé komory srdeční u osob s metabolickým syndromem
- Nutraceutika a jejich ovlivnění mírného kardiometabolického rizika
- Princip účinku medu v léčbě chronických i infikovaných ran
- Superoxidovaný roztok a jeho využití v léčbě ran
Nejčtenější v tomto čísle
- Silk garments plus standard care compared with standard care for treating eczema in children: A randomised, controlled, observer-blind, pragmatic trial (CLOTHES Trial)
- Talking sensibly about depression
- A new cascade of HIV care for the era of “treat all”
- Fresh fruit consumption in relation to incident diabetes and diabetic vascular complications: A 7-y prospective study of 0.5 million Chinese adults