
Signature Gene Expression Reveals Novel Clues to the Molecular Mechanisms of Dimorphic Transition in
Penicillium marneffei is a significant dimorphic fungal pathogen capable of causing lethal systemic infections. It grows in a yeast-like form at mammalian body temperature and a mold-like form at ambient temperature. The thermal dimorphism of P. marneffei is closely related to its virulence. In the present study, we re-sequenced the genome of P. marneffei using Illumina and PacBio sequencing technologies, and simultaneously assembled these newly sequenced reads in different lengths with previously obtained Sanger sequences. This hybrid assembly greatly improved the quality of the genome sequences. Next, we used RNA-seq to measure the global gene expression of P. marneffei at different phases and during dimorphic phase transitions. We found that 27% of genes showed signature expression patterns, suggesting that these genes function at different stages in the life cycle of P. marneffei. Moreover, genes with same expression patterns tend to be clustered together as neighbors to each other in the genome, suggesting an orchestrated transcriptional regulation for multiple neighboring genes. Over-expression of the MADS-box transcription factor, madsA, located in one of these clusters, confirms the function of this gene in driving the yeast-to-mycelia phase transition irrespective of the temperature cues. Our data also implies diverse roles of secreted proteins and non-coding RNAs in dimorphic transition in P. marneffei.
Published in the journal:
. PLoS Genet 10(10): e32767. doi:10.1371/journal.pgen.1004662
Category:
Research Article
doi:
https://doi.org/10.1371/journal.pgen.1004662
Summary
Penicillium marneffei is a significant dimorphic fungal pathogen capable of causing lethal systemic infections. It grows in a yeast-like form at mammalian body temperature and a mold-like form at ambient temperature. The thermal dimorphism of P. marneffei is closely related to its virulence. In the present study, we re-sequenced the genome of P. marneffei using Illumina and PacBio sequencing technologies, and simultaneously assembled these newly sequenced reads in different lengths with previously obtained Sanger sequences. This hybrid assembly greatly improved the quality of the genome sequences. Next, we used RNA-seq to measure the global gene expression of P. marneffei at different phases and during dimorphic phase transitions. We found that 27% of genes showed signature expression patterns, suggesting that these genes function at different stages in the life cycle of P. marneffei. Moreover, genes with same expression patterns tend to be clustered together as neighbors to each other in the genome, suggesting an orchestrated transcriptional regulation for multiple neighboring genes. Over-expression of the MADS-box transcription factor, madsA, located in one of these clusters, confirms the function of this gene in driving the yeast-to-mycelia phase transition irrespective of the temperature cues. Our data also implies diverse roles of secreted proteins and non-coding RNAs in dimorphic transition in P. marneffei.
Introduction
Systemic dimorphic fungi are a group of phylogenetically diverse fungal pathogens which are often geographically restricted but pose an increasing threat to the general population, particularly for immunosuppressed hosts. When transferring between their inhabited environments and human body, morphologic shifts seem necessary for dimorphic fungi to adapt to new circumstance [1]. The phase transitions are regulated by temperature in systemic dimorphic fungi, which take the saprotrophic mycelial form at the lower ambient temperature and the pathogenic yeast form at the higher host body temperature [2]. The mycelium-to-yeast (M-Y) transition is believed to be critical for the pathogenicity of systemic dimorphic fungi because the yeast form is the in vivo cellular form that is capable of evading the host immune system [3], while the yeast-to-mycelium (Y-M) transition is crucial to maintain an environmental reservoir, since these fungi are not directly transmitted between mammalian hosts [4]. Thus, the mechanisms of dimorphism attract great interest within the scientific community [5].
Penicillium marneffei is a strictly thermally dimorphic fungus [6], recently renamed Talaromyces marneffei [7]. At 25°C, P. marneffei grows vegetatively as mycelia and shows typical multinuclear mold morphology. At 37°C, the fungus undergoes the phase transition with concomitant coupling of nuclear and cellular division to form uninucleate, single-celled yeasts. To date, over forty genes have been functionally characterized in P. marneffei (see review [8]), yet genetic mechanisms underlying dimorphism remain elusive. Dimorphic development in P. marneffei is a complex process controlled by a suite of genetic elements. The recent advent of high-throughput approaches has brought new promise for the utilization of genomic and systematic applications to complement the conventional single-gene approaches to identify factors and processes that contribute to dimorphism [9]–[13].
In the present study, we employed next-generation sequencing technologies to revisit the genome sequences of P. marneffei, and systematically identified signature expression changes associated with the dimorphic switch. Specifically, we conducted a hybrid assembly of the P. marneffei genome with data derived from three different sequencing technologies. We also utilized RNA-seq to characterize P. marneffei transcriptomes at various stages of its life cycle. Using the over-expression experiment, we investigated the function of an important transcription factor and showed that the activation of this transcription factor can induce mycelial growth of P. marneffei at 37°C. We provided evidence for the potential roles of secreted proteins, non-coding RNAs, and secondary structural transition of mRNA transcripts in regulating thermal dimorphism in P. marneffei.
Results
Hybrid assembly of the P. marneffei genome
We previously sequenced the genome of P. marneffei PM1 strain using Sanger sequencing and obtained 190.3 Mb of shortgun sequences [14]. In the present study, we re-sequenced the genome using Illumina and PacBio sequencing technologies. We obtained 4.12 Gb of Illumina reads and 91.70 Mb of PacBio reads. The length of PacBio reads ranged from 50 to 15,433 bp with an average of 1,885 bp. As a result, we have sequenced the P. marneffei genome using all three generations of sequencing technologies. To take full advantage of reads generated by these different technologies, we adapted a hybrid assembly strategy. The first step of the hybrid assembly involves the error correction for PacBio long reads using massive high-throughput short Illumina reads [15]. This step is essential because the high error rate of PacBio reads would otherwise interfere with the overall assembly. The error correction algorithm is implemented in PacBioToCA of Celera Assembler [16]. The length of seed is a key parameter that influences the results of mapping and error correction. To determine the influence of the seed length on the performance of error correction, we compared the error-corrected PacBio reads against the reads from the Sanger assembly. We found that the accuracy of error correction was not sensitive to the length of seed, while the seed length of 12 produced the largest yield of error-corrected PacBio reads (Figure S1). Thus, the seed length of 12 was used for the error correction. The second step of hybrid assembly is to determine the optimal seed length for full assembly and use it to assemble all three types of reads simultaneously. To do so, we performed the full assembly multiple times by setting the length of seed from 16 to 75. We evaluated the assembly results by the N50 scaffold size (Figure S2). We chose the optimal seed length 62 for the full assembly. The final full assembly was performed using Celera Assembler [16]. To illustrate the performance of hybrid assembly, we also assembled the genome using only Sanger reads and Illumina reads, without PacBio reads. Phrap was used to assemble Sanger reads, while ABySS [17] and SOAPdenovo [18] were used to assemble Illumina reads. Indeed, hybrid assembly produced results better than those obtained by the other non-hybrid means of assembly (Table 1). In addition, we adapted a procedure described in [19] to use the paired-end RNA-seq reads (described below) to further improve the assembly.

The newly assembled genome consists of 28.35 Mb of sequences, distributed on 216 scaffolds. The N50 reaches 678.24 kb, which is 3.5 times longer than the draft assembly we previously reported [14].The longest scaffold is 1.28 Mb. To our knowledge, this is the first time that all three generations of sequencing technologies were used in de novo genome assembly for a fungal genome.
Using ab initio gene prediction, subsequently improved by using expression data, we annotated 9,480 protein-coding genes and 571 non-coding RNA genes (i.e., genomic loci that can be transcribed into mRNA molecules but with minimal protein-coding potential) (Table S1). For these protein-coding genes, we annotated 6,066 by searching the Swiss-Prot database using BLASTP (Table S2), 5,890 with 1,687 gene ontology (GO) terms (Table S3), and 7,358 with 5,340 IPR names (Table S4).
Patterns of gene expression under various growth conditions
We used RNA-seq to determine the global gene expression of P. marneffei grown on PDA media under four experimental treatments: (1) stable growth at 37°C as yeasts (stable yeast, Y), (2) yeasts grown at 37°C transferred to 25°C for 6 hours (yeast-to-mycelium, Y-to-M), (3) mycelia grown at 25°C transferred to 37°C for 6 hours (mycelium-to-yeast, M-to-Y), and (4) stable growth at 25°C as mycelia (stable mycelium, M). For each treatment, two biological replicates were performed. Highly consistent measures between two replicates were obtained for all treatments (Figure S3). Among 10,051 genes, 92.5% were expressed (FPKM>1.0 in at least one condition).
We used a four-digit code to denote the expression pattern for each gene. The code is a combination of four “1” or “0”, indicating relatively high or low expression of a gene, respectively, under the four treatments. For example, the expression level of GQ26_0010080 under the second treatment was significantly higher than those of the other three treatment (average FPKM: 182.3, 518.8, 176.8, and 181.9); the gene's expression pattern is “0100”. Note that the expression levels of a gene were compared between treatments of the same gene, not against expression levels of other genes. Genes with the same expression pattern code do not necessarily have the similar overall expression level. This four-digit code system allowed us to create 16 expression patterns and classified all genes into one of pattern groups. The 16 patterns included “0000” for genes that were not expressed (FPKM<1.0) under all four conditions and “1111” for genes expressed under four conditions almost equally. The rest of 14 patterns (such as “0100” and “0011”) were collectively named signature patterns. A total of 2,718 P. marneffei genes were classified into one of signature pattern groups (Table S1). Each of the 14 signature patterns is presumably implicated at a certain stage in the life cycle of P. marneffei (Figure 1). For genes in each pattern group, we tabulated the GO terms associated with gene functions and used REVIGO [20] to summarize information by merging semantically similar GO terms into non-redundant, high-level phrases (Figure 2, Table S5).


Clusters of genes with same expression patterns
We examined the distribution of genes with different expression patterns along each scaffold. We found that a number of genes with the same expression patterns form gene clusters (Figure 3). The similarity in expression patterns suggest that the genes sharing the same clusters and thus genetically linked may also play similar or related roles in regulating the life cycle of P. marneffei. Of 2,718 genes with 14 signature patterns, 283 (10.4%) are located in 73 clusters (Table 2). These clusters are composed of 3 to 13 genes, scattered all over scaffolds. The size of the clusters (i.e., the number of genes in a cluster) is independent of the type of expression pattern. For example, 23.5% “0100” genes are located within the same clusters. In contrast, 11.4% “0011” and 8.2% “1000” are located in clusters, but the clusters representing each of these patterns have comparable total numbers of genes (498, 517, and 499 for “0100”, “0011” and “1000”, respectively).

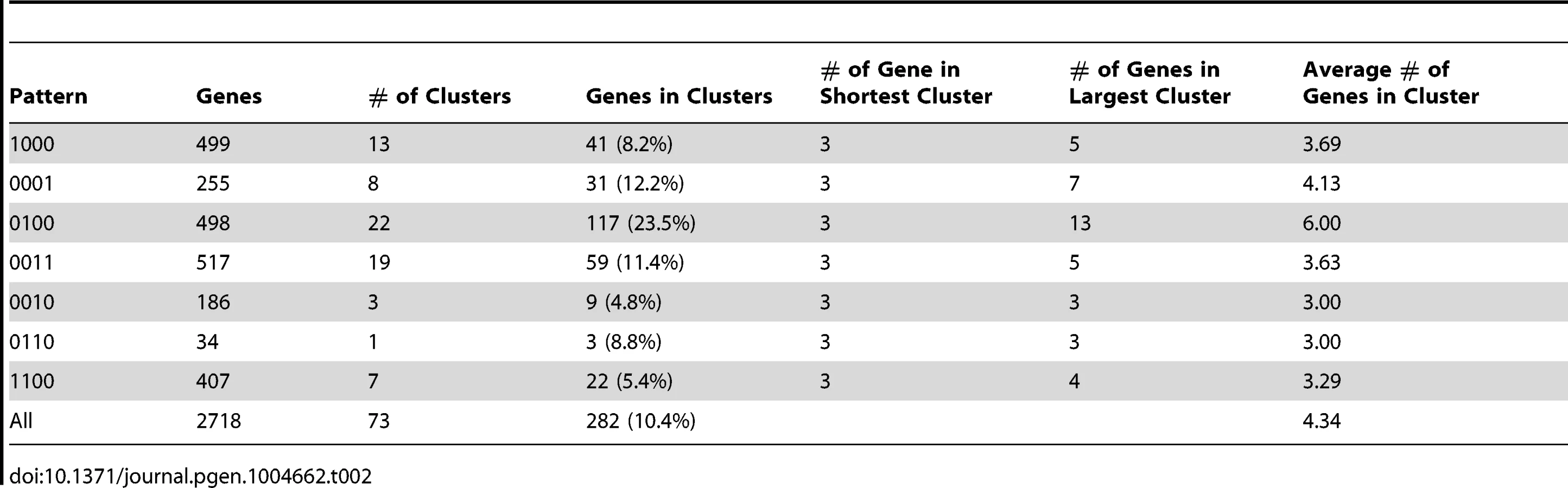
MADS-box transcription factors in P. marneffei
Transcriptional activation or suppression of downstream target genes in response to different stimuli is often accomplished by transcription factors [21], [22]. In P. marneffei, genes with three transcription factor domains are the most abundant: MADS-box (IPR002100), CBF/NF-Y/archaeal histone (IPR003958), and Fork head (IPR001766). In particular, the MADS-box transcription factor gene family is clearly expanded in the P. marneffei lineage (Figure 4), while the numbers of the other two types of transcription factors are comparable to other fungal species. MADS-box transcription factors are known to regulate cell-type-specific transcription in Saccharomyces cerevisiae [23] and Schizosaccharomyces pombe [24], [25].
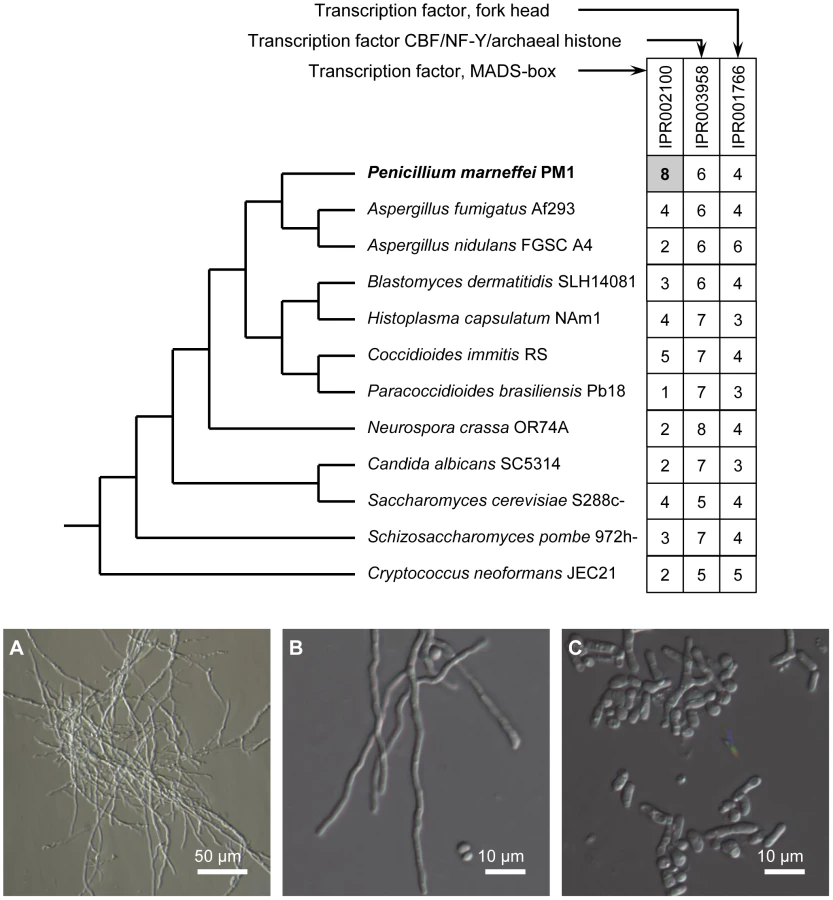
Interestingly, three (out of eight) P. marneffei MADS-box transcription factors are separately located in three “0100” clusters (highly expressed in Y-to-M transition). We determined the expression level for genes in one of the clusters using quantitative RT-PCR (qRT-PCR). In this particular cluster, the MADS-box transcription factor (GQ26_0030130) is located in the middle of a group of 12 genes with the expression pattern “0100”. Our qRT-PCR results confirmed that the expression level of all genes in this cluster is significantly up-regulated during Y-M transition (Figure 5). We named the gene GQ26_0030130 madsA. In wild-type P. marneffei, the expression of madsA is up-regulated during Y-M transition, which suggests the role of this gene in stimulating mycelial development. To characterize its function, we overexpressed madsA in P. marneffei (madsAOE) (Materials and Methods). At 25°C, the madsAOE mutant grew as mycelia, showing no morphological differences compared to the wild-type strain. Strikingly, at 37°C, mycelial cells were induced in the madsA-overexpressed strain (Figure 4), the wild type cells grew strictly as yeasts at this high temperature. This further supports our hypothesis that MadsA controls the phase transition from yeast to mycelium in P. marneffei.

Secreted proteins in P. marneffei
Secreted proteins facilitate the attachment of P. marneffei conidia to the bronchoalveolar epithelium of the host [26]. In the newly assembled P. marneffei genome, we predicted 434 proteins that are likely to be secreted extracellularly (Materials and Methods). The majority of them (339 or 78.1%) were among those in the 14 signature expression patterns. These predicted secreted proteins appear disproportionally enriched in most of the signature patterns (Table 3). This finding suggests that secreted proteins may play diverse roles at different stages of the P. marneffei life cycles. Furthermore, clusters of genes encoding secreted proteins have been identified in non-human pathogenic fungi [27], [28]. For example, 12 clusters containing 79 secreted proteins and ranging from 3 to 26 genes were identified in Ustilagos maydis [27], and 121 gene clusters containing 453 secreted proteins and ranging from 3 to 11 genes per cluster in Monacrosporium haptotylum [28]. However, in the P. marneffei genome, we only found 5 clusters of secreted proteins, each with just 3 genes, suggesting that the clustering organization of secreted proteins per se is not important for P. marneffei pathogenicity.

Temperature-dependent RNA structural transitions in P. marneffei
In a previous study, we found that the expression of most fungal heat-responsive genes in P. marneffei are not up-regulated at 37°C [13]. This led us to believe that P. marneffei may take a distinct strategy of genetic regulation at the elevated temperature beyond known heat-shock proteins [13]. RNA structure is crucial for gene regulation and function [29]. For example, RNA structures near the start codon of the URE2 transcript reduced its translation rate in S. cerevisiae [30]. Parallel analysis of RNA structures with temperature elevation (PARTE) of S. cerevisiae revealed that thermodynamically unstable structures are enriched in ribosome binding sites in the 5′-UTRs of mRNAs [31], which suggested that RNA thermometers can function as an evolutionarily conserved heat shock mechanism in eukaryotes [32].
Here we hypothesized that the structural transition of mRNAs at different temperatures is one of the mechanisms underlying thermal dimorphism of P. marneffei. To this end, we employed a computational approach based on RNAfold v2.1.7 [33] to determine the secondary structure of P. marneffei mRNAs at 25 and 37°C. Through the structural comparison, we identified the mRNAs whose predicted structures are substantially different at the two temperatures. The structural differentiation was assessed by focusing on the region of −9 to +6 base positions around the translation initiation codon. Nucleotides in this region have been shown to be important for the regulation of translation initiation [34]. We expected that this region in mRNAs of temperature-sensitive genes would be more “structurally open” (i.e., contains more unpaired bases) at 37 than at 25°C, facilitating the translation of the mRNAs into proteins. Accordingly, the expression of these genes might also be up-regulated at 37°C. We identified 59 mRNAs structurally more open at 37 than 25°C (Table S6), which was indicated by at least eight more unpaired bases in the translation initiation region at 37°C. Fourteen of these mRNAs are transcribed from genes with one of signature expression patterns (Table S7). Three are transcribed from genes with the expression pattern of “1010”, which indicates that their transcription is highly sensitive to 37°C (Figure 6).

Non-coding RNA genes in P. marneffei
We predicted 571 potential non-coding RNA (ncRNA) genes whose transcripts have no or minimal protein-coding potential, indicated by the lack of significant hits when comparing the transcripts against sequences of the Genbank database using the BLASTX algorithm. The expression patterns of these ncRNAs are more likely to be “0010”, “1010”, “1110”, and “1100” (Table 3). Notably, 8.4% (49 of 571) of the ncRNAs have an expression pattern of “0010”. This figure is significantly higher than the background frequency of 1.9% (i.e., 186 of 10,051 total genes have the pattern of “0010”).
Because ncRNAs are often partially complementary to other molecules and take effect through binding to their targets, we searched all the potential binding sites of the 571 ncRNAs in P. marneffei transcripts using the BLASTN-short algorithm. We found a total of 569 genes containing at least one potential ncRNA binding site (Table S8). The expression patterns of these target genes tended to be those related to M-Y transition, including 37°C-sensitive (“1010”), M-Y transition specific (“0010”), and mycelium and M-Y transition (“0011”)(P = 5.6×10−8, 3.5×10−5, and 0.013, respectively; χ2 test). Additionally, we found 89 potential binding sites located in the structurally flexible regions as indicated by the differential secondary structure prediction at 25 and 37°C.
Discussion
Whole-genome sequencing represents a powerful and critical tool for functional genomic studies. Various sequencing technologies have been developed for genome sequencing, but none of them is prefect—all of these technologies have their own advantages and drawbacks. Illumina, for example, delivers high-throughput, inexpensive, and accurate sequence information [35]. However, template amplification is required before sequencing with Illumina, which could cause amplification artifacts [36] and biased coverage [37] related to the chemical-physical properties of the genome. More importantly, Illumina produces short reads, which decreases the continuities of contigs [38]. By contrast, the PacBio sequencer does not require template amplification and thus reduces the composition bias, and is able to produce reads over 10 kb long [39]. These features allow PacBio to bypass the short-read issues of Illumina, and confer the potential advantage to resolve complex repeat regions of the genome. However, the error rate of PacBio reads is as high as 15% [40]. To solve the problem, we used the error correction algorithm to correct as many as possible of the errors in PacBio reads by mapping Illumina reads to them. The Sanger sequencing, representing an earlier generation technology, is still the “gold standard” for validation; however, partially due to the financial considerations, researchers are inclined to use as few Sanger reads as possible. Here, we have set to combine three different generations of sequencing technologies, namely Sanger, Illumina, and PacBio, to produce a better reference P. marneffei genome. The hybrid assembly allowed the advantages of different technologies to complement to each other to improve the quality of assembly. There were more reads that could be mapped to the hybrid assembly of PM1 than the previous one assembled with only Sanger reads [14]. Our results showcased the possibility of improving the overall quality of genome assembly through re-sequencing with diverse platforms. Our strategy is a significant improvement in the balance of cost and genome sequence quality.
It is noteworthy that genome sequences of another P. marneffei strain ATCC18224 are available in Genbank (Accession ABAR00000000), which are different from those of P. marneffei strain PM1 [14]. Our assembly showed that PM1 may have eight chromosomes because telomere tandem repeat sequences were identified at the ends of 16 scaffolds. In contrast, seven chromosomes are present in the ATCC18224 assembly. A karyotype study also suggested seven chromosomes, but, at the same time, the same study estimated that the genome size was between 25.7 to 26.7 Mb [41], which was smaller than the estimates for ATCC18224 and PM1 (∼29.0 Mb for both). It is possible that a chromosome in size of ca. 2 Mb was overlooked by the karyotype study. Nevertheless, more studies are needed to confirm the number of chromosomes of P. marneffei and reconcile assemblies from different strains in the future.
Expression levels at four conditions were considered for each gene as part of the expression pattern analysis. This allowed the multiple-way comparisons of gene expression in all conditions and could, in theory, produce a large number of patterns (i.e., all possible combinations of the results of gene expression level comparison between conditions). To simplify the patterns, we employed the “0”–“1” schema to define signature patterns that only capture the essential differences between conditions. As a result, in the experimental data we collected, only 15 patterns (including “1111” representing equally expressed in all conditions) needed to be considered. This significant reduction of the theoretical number of possible expression-level combinations to the number of observed expression patterns in reality suggested a functional constraint in the biological system of P. marneffei gene expression. We mapped all expression patterns with associated genes onto the different biological stages in the life cycle of P. marneffei (Figure 1). This represents, so far, the most comprehensive expression pattern-based classification of P. marneffei genes. One immediate insight we gain based on the classification was the discovery of expression pattern clusters. Genes in the same cluster have the same expression patterns, probably due to coordinated regulation of these genes that have similar or related functions.
The madsA gene is in the cluster of high expression during the morphological transition from the yeast to mycelium form. Indeed, over-expression of this MADS-box gene resulted in the morphological change to mycelium form at 37°C that restricts the wild type P. marneffei in the yeast form. This MADS-box transcription factor is located in the cluster of a series of genes with the same expression patterns. The induced morphological change validated the function of this gene in regulating morphological development. This result also demonstrated the usefulness of the signature expression patterns and the clusters of genes with the same patterns. This concept was further illustrated by a series of discoveries involving secreted proteins, RNA structural transition, and ncRNAs. First, 78.1% of predicted secreted proteins have expression patterns that are found among the 14 signature patterns. The portion is significantly higher than that of randomly selected genes that have signature expression patterns (P<10−16, Χ2 test). Second, 23.7% (14 out of 59) of mRNAs with a highly differential structure at 25 and 37°C have a signature expression pattern. This suggests a widely-spread impact of the mRNA structural transition at different stages of P. marneffei development. Finally, our results describing the expression patterns of ncRNAs and their target genes suggest that ncRNAs may play a role in M-Y transition.
In summary, we have made several steps toward a better understanding of P. marneffei thermal dimorphism. Hybrid assembly combined the advantages of different sequencing technologies to improve the quality of genome assembly. Signature expression patterns allowed the prioritization of genes that potentially play important roles in growth regulation and dimorphic development. This strategy was applied to identify the potential master transcription factor, madsA, whose function in regulating yeast-to-mycelium transition was then experimentally validated. We anticipate that our overall strategy and approaches can also be used for studying other systemic fungal pathogens.
Materials and Methods
Genomic DNA preparation and sequencing
Sanger sequencing of P. marneffei strain PM1 was conducted in our previous study [14]. Briefly, genomic DNA was prepared from the arthroconidia of PM1 grown at 37°C as described [42]. Two genomic DNA libraries were made in pUC18 carrying insert sizes from 2.0–3.0 kb and 7.5–8.0 kb, respectively. DNA inserts were prepared by physical shearing using the sonication method [43]. A total of 190.3 Mb of sequence data, which is equivalent to ∼6.6× coverage of the genome, were generated by random shotgun Sanger sequencing. The draft genome sequences were assembled using Phrap (http://www.phrap.org/).
In the present study, the P. marneffei strain PM1 genome was re-sequenced using Illumina and PacBio sequencing technologies. The strain was cultured in Sabouraud's Dextrose Agar (SDA) at 25°C for 7 days. Sporulating colonies were covered by 1 ml of sterile phosphate buffed saline (PBS) containing 0.05% (v/v) TWEEN-20. The resulting mixture of conidia and hyphal fragments was withdrawn and filtered by Miracloth. The density of conidia in the filtrate was adjusted to 1×108 conidia/ml. 100 µl of adjusted conidial suspension was inoculated into 50 ml of Sabouraud's Dextrose Broth (SDB). After culturing at 37°C for 7 days, 5 ml of culture was transferred into another 45 ml of SDB and cultured at 37°C for 16 hours. Cells were collected by centrifugation at 3000×g for 5 min. Genomic DNA was extracted using E.Z.N.A. Fungal DNA Kit (Omega Bio-Tek Inc.), following the manufacturer's instructions with a slight modification: RNA was digested by RNase I instead of RNase A. High-throughput Illumina sequencing was performed by the Beijing Genomics Institute (BGI) Americas. Extracted genomic DNA was fragmented randomly and then DNA fragments around 500 bp in size were retained by electrophoresis. Adapters were ligated to DNA fragments. After cluster preparation, 90-bp pair-end sequencing was conducted. This resulted in raw data of 22,861,112 pairs of 90 bp pair-end reads. The reads were trimmed using fastx-trimmer version 0.0.13, based on the base-calling quality reported by FastQC v0.10.1. PacBio sequencing was conducted by the Biomedical Genomics Microarray Facility at University of California, San Diego. The template library, with 10-kb insert was prepared according to the manufacturer's specifications. The sequencing was carried out on a PacBio RS platform following the standard protocol with a C2 sequencing kit at the 1×120-min acquisition mode. The run was carried out with diffusion-based loading and analyzed using the standard primary data analysis. Finally, the SMRT cell of PacBio system yielded 91.70 Mb of sequences from a total of 48,645 continuous long reads.
Genome assembly
We employed Phrap v1.090518 or the assembly of Sanger reads alone using various values of -minmatch ranging from 14 (default value) to 30. The default value provides the best assembly with a total length of 28.92 Mb and a scaffold N50 of 24.08 kb after removing contigs shorter than 500 bp. Two software tools were used independently for assembling Illumina reads. For ABySS v1.3.7 [17], different values for parameter k-mer size (-k) were used, ranging from 13 to 79. A run with a minimum-required contig size of 100 bp and a k-mer length of 28 nt resulted in an assembly with a total length of 28.50 Mbp and a scaffold N50 of 211.24 kbp after removing scaffolds less than 500 bp. For SOAPdenovo v2.01 [18], different values for parameter k-mer size (-K) were used with odd numbers of 13 to 79. A run with a k-mer length of 57 nt resulted in an assembly with a total length of 27.95 Mbp and a scaffold N50 of 170.68 kbp after removing scaffolds less than 500 bp. Error correction of PacBio RS reads were implemented by PacBioToCA of Celera Assembler version 7.0 [16] using Illumina reads [15] with seed length (-MerSize) ranging from 10 to 20. Corrected reads were aligned to the contigs assembled with Sanger reads by BLASTN to estimate the accuracy of error correction. Because seed length affected amount of corrected reads but not the identity, the error correction of PacBio reads was performed with a seed length of 12 to produce the largest amount of corrected read outputs. Hybrid de novo assembly was performed using Celera Assembler with Sanger, Illumina, and corrected PacBio reads. The different seed lengths ranging from 19 to 79 were tested. A run with a seed length of 62 resulted in the best assembly as indicated by the N50 scaffold size. RNA-seq reads were used to improved scaffolds using customized scripts based on the principle described in a previous study [19].
Gene prediction and annotation
Protein-coding genes were predicted by using FGENESH (SoftBerry, Mount Kisco, NY) [44] with genome-specific parameters of Penicillium. Aided by a total of 107.4 million paired-end RNA-seq reads, 739 additional genes were annotated that had been missed by the ab initio prediction. These genes were then searched against the non-redundant protein database of Genbank using BLASTX to measure the coding potential. Together, we annotated a total of 9,480 protein-coding genes and 571 non-coding RNA genes. To further annotate predicted genes, we searched motifs and domains using InterProScan v5.3-46.0 [45] against publicly available databases, including Pfam, PRINTS, PROSTIE, ProDom, SMART, and PANTHER, and then retrieved the GO annotation from the results of InterProScan for all genes.
RNA preparation and sequencing
At the beginning of the experiment, conidia of strain PM1 were inoculated onto SDA plates and cultured at 25 and 37°C for a week. The germinated cells were transferred onto new SDA plates every week for 2 weeks to establish stable colonies of either the mycelial or yeast growth form. One week before the extraction of total RNA, the homogenous cells were cultured on new SDA plates to obtain fresh cells. For temperature switch experiments, yeast or mycelial growth plates were transferred to 25 or 37°C for 6 hours, respectively. The total RNAs were extracted from each condition for two independent biological replicates using the E.Z.N.A. fungal RNA kit (Omega Bio-Tek), following the manufacturer's instructions with DNase I digestion to eliminate genomic DNA. We adjusted the total RNA concentration according to the DNA content before the standard poly(A)+ RNA-seq was performed. RNA was quantified using Qubit 2.0 fluorometer (Life Technologies, Grand Island, NY). Finally, we obtained ∼13 million 90-bp paired-end reads for each sample. The reads were trimmed using fastx-trimmer based on the quality reported by FastQC.
Gene expression analysis
RNA-seq short reads were mapped to the annotated genomes using Tophat v2.0.11 [46]. For each sample, ∼2.0 Gb of reads was mapped, representing ∼100× coverage of P. marneffei transcriptome. Using SAMMate [47], the gene expression level was measured in FPKM (fragments per kilobase of exon per million fragments mapped) [48]. For each gene, expression levels associated with each of the four experimental treatments were compared to each other and the relative levels are marked by 1 indicating highly expressed and 0 indicating lowly expressed. Genes that were not expressed at all for the four conditions have a pattern of “0000”, while the house-keeping genes consistently expressed at similar levels under all four conditions have a pattern of “1111”. Besides the two patterns for un-expressed and house-keeping genes, 14 other signature patterns (e.g., “1100” and “0100”) were denoted.
Quantitative real-time PCR
The P. marneffei strain was pre-cultured under the same conditions for preparing the RNA-seq samples. The total RNAs were also extracted using the same procedure described above. The concentrations of total RNA were adjusted to 100 µg/ml. Real-time RT-PCR assays were performed using iTaq Universal SYBR Green One-Step Kit (Bio-Rad Laboratories) with primers shown in Table S9. Template total RNA was reverse transcribed and amplified in a Bio-Rad CFX96 Real-Time PCR Detection System (Bio-Rad Laboratories) in 20-µl reaction mixtures containing 10 µl of iTaq universal SYBR Green reaction mix (2×), 0.25 µl of iScript reverse transcriptase, 2 µl of 100 nM of forward and reverse primers mix, 1 µl of total RNA template, and 6.75 µl of nuclease-free water, at 50°C for 10 min, 95°C for 1 min, followed by 30 cycles of 95°C for 10 s and 58°C for 30 seconds. Melting curves were measured from 65°C to 95°C with 0.5°C of increment. Results from actin (actA) were used for normalization. There is no significant difference in the gene expression levels of actA in different cell types (conidia, mycelia, and yeast cells) [49]. Glyceraldehyde-3-phosphate dehydrogenase-encoding gene (gpdA) was used as a negative control to show that the house-keeping gene was expressed constantly across experimental conditions [50].
Overexpression of madsA
The propagation of plasmid DNA was performed by chemical transformation of Escherichia coli TOP10 cells (Invitrogen) according to the manufacturer's instructions. Cells were grown overnight at 37°C on Luria-Bertani broth plates supplemented with 50 µg/ml ampicillin, on a 250 rpm shaking incubator. We selected the promoter of tefA (transcription elongation factor alpha) to overexpress madsA because tefA is a house-keeping gene that highly expressed in all contidions. The tefA(p)::madsA::tefA(t) fragment was generated by fusion PCR. The promoter region of tefA (PMG0060610) was amplified by PCR with forward primer 5′-GAAGATCTTAAGAATTCACTACCAGCAACC-3′ and reverse primer 5′-GGTTCGGTGCCAGCCATGGTGAAGGTTGTGTGTG-3′. The terminator region was amplified with forward primer 5′-TCCGGCGATTGTGGTGAGTGCACGATCTTGGGTG-3′ and reverse primer 5′-GAAGATCTCTATCGCTTCGCACTGTACATA-3′. The coding region of madsA was amplified with forward primer 5′-CACACACAACCTTCACCATGGCTGGCACCGAACC-3′ and reverse primer 5′-CACCCAAGATCGTGCACTCACCACAATCGCCGGA-3′. The fusion PCR product was then ligated into the plasmid pAN7-1 [51] at the BglII restriction site, resulting in plasmid pAN701-1. The resultant plasmid was linearized with AhdI and transformed to wildtype strain PM1 according to previous publications [52], [53]. SDA supplemented with 200 µg/ml hygromycin B was used as selection medium.
Prediction of secreted proteins
Multiple software tools were jointly used to predict the secreted proteins [54]. WoLF PSORT (http://www.genscript.com/psort/wolf_psort.html [55], SignalP 4.1 (http://www.cbs.dtu.dk/services/SignalP/) [56], and Phobius (http://phobius.sbc.su.se/) [57] were employed to identify signal peptide signatures. The default parameters were used for all the programs. For WoLF PSORT, proteins were considered to be expressed if their extracellular score was larger than 17 [58]. Proteins predicted to be signal-peptide positive by all three programs were taken through two additional filtering steps. First, we excluded possible membrane proteins using TMHMM v2.0 (http://www.cbs.dtu.dk/services/TMHMM/) [59]—a protein was considered to be membrane protein if its transmembrane domains were not located in the first 70 amino acids of the N-terminus [54]. Second, we removed possible endoplasmic reticulum (ER) targeting proteins, predicted by using PS-Scan (http://prosite.expasy.org/scanprosite/) [60] with Prosite accession PS00014. The remaining proteins were considered secreted proteins and used in the subsequent analyses.
Data access
All data generated are deposited into the NCBI BioProject database under accession numbers: PRJNA251717 and PRJNA251718. More information can be found online (http://pmarneffei.genomezoo.net).
Supporting Information
{kind=link}
{kind=link}
{kind=link}
Zdroje
1. CooneyNM, KleinBS (2008) Fungal adaptation to the mammalian host: it is a new world, after all. Current Opinion in Microbiology 11 : 511–516.
2. RappleyeCA, GoldmanWE (2006) Defining virulence genes in the dimorphic fungi. Annual Review of Microbiology 60 : 281–303.
3. KleinBS, TebbetsB (2007) Dimorphism and virulence in fungi. Current Opinion in Microbiology 10 : 314–319.
4. Mandell GL, Bennett JE, Dolin R (2010) Mandell, Douglas, and Bennett's principles and practice of infectious diseases. Philadelphia, PA: Churchill Livingstone/Elsevier.
5. NemecekJC, WuthrichM, KleinBS (2006) Global control of dimorphism and virulence in fungi. Science 312 : 583–588.
6. CooperCR, VanittanakomN (2008) Insights into the pathogenicity of Penicillium marneffei. Future Microbiology 3 : 43–55.
7. SamsonRA, YilmazN, HoubrakenJ, SpierenburgH, SeifertKA, et al. (2011) Phylogeny and nomenclature of the genus Talaromyces and taxa accommodated in Penicillium subgenus Biverticillium. Studies in Mycology 159–183.
8. BoyceKJ, AndrianopoulosA (2013) Morphogenetic circuitry regulating growth and development in the dimorphic pathogen Penicillium marneffei. Eukaryotic Cell 12 : 154–160.
9. XiLY, XuXR, LiuW, LiXQ, LiuYL, et al. (2007) Differentially expressed proteins of pathogenic Penicillium marneffei in yeast and mycelial phases. Journal of Medical Microbiology 56 : 298–304.
10. ChandlerJM, TreeceER, TrenaryHR, BrennemanJL, FlicknerTJ, et al. (2008) Protein profiling of the dimorphic, pathogenic fungus, Penicillium marneffei. Proteome Science 6 : 17.
11. LinX, RanY, GouL, HeF, ZhangR, et al. (2012) Comprehensive transcription analysis of human pathogenic fungus Penicillium marneffei in mycelial and yeast cells. Medical Mycology 50 : 835–842.
12. PasrichaS, PayneM, CanovasD, PaseL, NgaosuwankulN, et al. (2013) Cell-type-specific transcriptional profiles of the dimorphic pathogen Penicillium marneffei reflect distinct reproductive, morphological, and environmental demands. G3-Genes Genomes Genetics 3 : 1997–2014.
13. YangE, WangG, WooPCY, LauSKP, ChowWN, et al. (2013) Unraveling the molecular basis of temperature-dependent genetic regulation in Penicillium marneffei. Eukaryotic Cell 12 : 1214–1224.
14. WooPCY, LauSKP, LiuB, CaiJJ, ChongKTK, et al. (2011) Draft genome sequence of Penicillium marneffei strain PM1. Eukaryotic Cell 10 : 1740–1741.
15. KorenS, SchatzMC, WalenzBP, MartinJ, HowardJT, et al. (2012) Hybrid error correction and de novo assembly of single-molecule sequencing reads. Nature Biotechnology 30 : 693–700.
16. MillerJR, DelcherAL, KorenS, VenterE, WalenzBP, et al. (2008) Aggressive assembly of pyrosequencing reads with mates. Bioinformatics 24 : 2818–2824.
17. SimpsonJT, WongK, JackmanSD, ScheinJE, JonesSJM, et al. (2009) ABySS: A parallel assembler for short read sequence data. Genome Research 19 : 1117–1123.
18. LiRQ, ZhuHM, RuanJ, QianWB, FangXD, et al. (2010) De novo assembly of human genomes with massively parallel short read sequencing. Genome Research 20 : 265–272.
19. MortazaviA, SchwarzEM, WilliamsB, SchaefferL, AntoshechkinI, et al. (2010) Scaffolding a Caenorhabditis nematode genome with RNA-seq. Genome Research 20 : 1740–1747.
20. SupekF, BosnjakM, SkuncaN, SmucT (2011) REVIGO Summarizes and Visualizes Long Lists of Gene Ontology Terms. PLoS One 6: e21800.
21. BarreraLO, RenB (2006) The transcriptional regulatory code of eukaryotic cells insights from genome-wide analysis of chromatin organization and transcription factor binding. Current Opinion in Cell Biology 18 : 291–298.
22. HeintzmanND, RenB (2007) The gateway to transcription: identifying, characterizing and understanding promoters in the eukaryotic genome. Cellular and Molecular Life Sciences 64 : 386–400.
23. ElbleR, TyeBK (1991) Both activation and repression of a-mating-type-specific genes in yeast require transcription factor Mcm1. Proceedings of the National Academy of Sciences of the United States of America 88 : 10966–10970.
24. NielsenO, FriisT, KjaerulffS (1996) The Schizosaccharomyces pombe map1 gene encodes an SRF/MCM1-related protein required for P-cell specific gene expression. Molecular & General Genetics 253 : 387–392.
25. YabanaN, YamamotoM (1996) Schizosaccharomyces pombe map1+ encodes a MADS-box-family protein required for cell-type-specific gene expression. Molecular and Cellular Biology 16 : 3420–3428.
26. LauSKP, TseH, ChanJSY, ZhouAC, CurreemSOT, et al. (2013) Proteome profiling of the dimorphic fungus Penicillium marneffei extracellular proteins and identification of glyceraldehyde-3-phosphate dehydrogenase as an important adhesion factor for conidial attachment. FEBS Journal 280 : 6613–6626.
27. KamperJ, KahmannR, BolkerM, MaLJ, BrefortT, et al. (2006) Insights from the genome of the biotrophic fungal plant pathogen Ustilago maydis. Nature 444 : 97–101.
28. MeerupatiT, AnderssonKM, FrimanE, KumarD, TunlidA, et al. (2013) Genomic mechanisms accounting for the adaptation to parasitism in nematode-trapping fungi. PLoS Genetics 9: e1003909.
29. WanY, KerteszM, SpitaleRC, SegalE, ChangHY (2011) Understanding the transcriptome through RNA structure. Nature Reviews Genetics 12 : 641–655.
30. ReinekeLC, KomarAA, CapraraMG, MerrickWC (2008) A small stem loop element directs internal initiation of the URE2 internal ribosome entry site in Saccharomyces cerevisiae. Journal of Biological Chemistry 283 : 19011–19025.
31. WanY, QuK, OuyangZQ, KerteszM, LiJ, et al. (2012) Genome-wide Measurement of RNA Folding Energies. Molecular Cell 48 : 169–181.
32. MortimerSA, KidwellMA, DoudnaJA (2014) Insights into RNA structure and function from genome-wide studies. Nat Rev Genet 15 : 469–479.
33. LorenzR, BernhartSH, SiederdissenCHZ, TaferH, FlammC, et al. (2011) ViennaRNA Package 2.0. Algorithms for Molecular Biology 6 : 26.
34. NakagawaS, NiimuraY, GojoboriT, TanakaH, MiuraK (2008) Diversity of preferred nucleotide sequences around the translation initiation codon in eukaryote genomes. Nucleic Acids Research 36 : 861–871.
35. MetzkerML (2010) Sequencing technologies - the next generation. Nature Reviews Genetics 11 : 31–46.
36. NiuBF, FuLM, SunSL, LiWZ (2010) Artificial and natural duplicates in pyrosequencing reads of metagenomic data. BMC Bioinformatics 11 : 187.
37. DohmJC, LottazC, BorodinaT, HimmelbauerH (2008) Substantial biases in ultra-short read data sets from high-throughput DNA sequencing. Nucleic Acids Research 36: e105.
38. KingsfordC, SchatzMC, PopM (2010) Assembly complexity of prokaryotic genomes using short reads. BMC Bioinformatics 11 : 21.
39. SchadtEE, TurnerS, KasarskisA (2010) A window into third-generation sequencing. Human Molecular Genetics 19: R227–R240.
40. BashirA, KlammerAA, RobinsWP, ChinCS, WebsterD, et al. (2012) A hybrid approach for the automated finishing of bacterial genomes. Nature Biotechnology 30 : 701–707.
41. GiffordTD, CooperCR (2009) Karyotype determination and gene mapping in two clinical isolates of Penicillium marneffei. Medical Mycology 47 : 286–295.
42. YuenK, PascalG, WongSSY, GlaserP, WooPCY, et al. (2003) Exploring the Penicillium marneffei genome. Archives of Microbiology 179 : 339–353.
43. FrangeulL, NelsonKE, BuchrieserC, DanchinA, GlaserP, et al. (1999) Cloning and assembly strategies in microbial genome projects. Microbiology 145 : 2625–2634.
44. SolovyevV, KosarevP, SeledsovI, VorobyevD (2006) Automatic annotation of eukaryotic genes, pseudogenes and promoters. Genome Biology 7: S10.
45. JonesP, BinnsD, ChangH-Y, FraserM, LiW, et al. (2014) InterProScan 5: genome-scale protein function classification. Bioinformatics 30 : 1236–1240.
46. KimD, PerteaG, TrapnellC, PimentelH, KelleyR, et al. (2013) TopHat2: accurate alignment of transcriptomes in the presence of insertions, deletions and gene fusions. Genome Biology 14: R36.
47. XuG, DengN, ZhaoZ, JudehT, FlemingtonE, et al. (2011) SAMMate: a GUI tool for processing short read alignments in SAM/BAM format. Source Code for Biology and Medicine 6 : 2.
48. MortazaviA, WilliamsBA, MccueK, SchaefferL, WoldB (2008) Mapping and quantifying mammalian transcriptomes by RNA-Seq. Nature Methods 5 : 621–628.
49. KummasookA, TzarphmaagA, ThirachS, PongpomM, CooperCR, et al. (2011) Penicillium marneffei actin expression during phase transition, oxidative stress, and macrophage infection. Molecular Biology Reports 38 : 2813–2819.
50. ThirachS, CooperCR, VanittanakomN (2008) Molecular analysis of the Penicillium marneffei glyceraldehyde-3-phosphate dehydrogenase-encoding gene (gpdA) and differential expression of gpdA and the isocitrate lyase-encoding gene (acuD) upon internalization by murine macrophages. Journal of Medical Microbiology 57 : 1322–1328.
51. WooPCY, ChongKTK, LauCCY, WongSSY, LauSKP, et al. (2006) A novel approach for screening immunogenic proteins in Penicillium marneffei using the ΔAFMP1 ΔAFMP2 deletion mutant of Aspergillus fumigatus. FEMS Microbiology Letters 262 : 138–147.
52. WooPCY, LamCW, TamEWT, LeungCKF, WongSSY, et al. (2012) First discovery of two polyketide synthase genes for mitorubrinic acid and mitorubrinol yellow pigment biosynthesis and implications in virulence of Penicillium marneffei. PLoS Neglected Tropical Diseases 6: e1871.
53. LauSKP, ChowWN, WongAYP, YeungJMY, BaoJ, et al. (2013) Identification of microRNA-like RNAs in mycelial and yeast phases of the thermal dimorphic fungus Penicillium marneffei. PLoS Neglected Tropical Diseases 7: e2398.
54. MinXJ (2010) Evaluation of computational methods for secreted protein prediction in different Eukaryotes. Journal of Proteomics & Bioinformatics 3 : 143–147.
55. HortonP, ParkKJ, ObayashiT, FujitaN, HaradaH, et al. (2007) WoLF PSORT: protein localization predictor. Nucleic Acids Research 35: W585–W587.
56. PetersenTN, BrunakS, von HeijneG, NielsenH (2011) SignalP 4.0: discriminating signal peptides from transmembrane regions. Nature Methods 8 : 785–786.
57. KallL, KroghA, SonnhammerELL (2007) Advantages of combined transmembrane topology and signal peptide prediction - the Phobius web server. Nucleic Acids Research 35: W429–W432.
58. do AmaralAM, AntoniwJ, RuddJJ, Hammond-KosackKE (2012) Defining the predicted protein secretome of the fungal wheat leaf pathogen Mycosphaerella graminicola. PLoS One 7: e49904.
59. KroghA, LarssonB, von HeijneG, SonnhammerELL (2001) Predicting transmembrane protein topology with a hidden Markov model: Application to complete genomes. J Mol Biol 305 : 567–580.
60. de CastroE, SigristCJA, GattikerA, BulliardV, Langendijk-GenevauxPS, et al. (2006) ScanProsite: detection of PROSITE signature matches and ProRule-associated functional and structural residues in proteins. Nucleic Acids Research 34: W362–W365.
Štítky
Genetika Reprodukční medicínaČlánek vyšel v časopise
PLOS Genetics
2014 Číslo 10
Nejčtenější v tomto čísle
- The Master Activator of IncA/C Conjugative Plasmids Stimulates Genomic Islands and Multidrug Resistance Dissemination
- A Splice Mutation in the Gene Causes High Glycogen Content and Low Meat Quality in Pig Skeletal Muscle
- Keratin 76 Is Required for Tight Junction Function and Maintenance of the Skin Barrier
- A Role for Taiman in Insect Metamorphosis